Seminar Programme: Göttingen Dialog in Digital Humanities (2015)
The dialogs take place on Tuesdays at 17:00 during the Summer semester (from April 21th until July 14th). The venue of the seminars is to be announced, at the Göttingen Centre for Digital Humanities (GCDH). The centre's address is: Heyne-Haus, Papendiek 16, D-37073 Göttingen.
April 21
Yuri Bizzoni, Angelo Del Grosso, Marianne Reboul (University of Pisa, Italy)
Diachronic trends in Homeric translations
April 28
Stefan Jänicke, Judith Blumenstein, Michaela Rücker, Dirk Zeckzer, Gerik Scheuermann (Universität Leipzig, Germany)
Visualizing the Results of Search Queries on Ancient Text Corpora with Tag Pies
May 5
Jochen Tiepmar (Universität Leipzig, Germany)
Release of the MySQL based implementation of the CTS protocol
May 12
Patrick Jähnichen, Patrick Oesterling, Tom Liebmann, Christoph Kurras, Gerik Scheuermann, Gerhard Heyer (Universität Leipzig, Germany)
Exploratory Search Through Visual Analysis of Topic Models
May 19
Christof Schöch (Universität Würzburg, Germany)
Topic Modeling Dramatic Genre
May 26
Peter Robinson (University of Saskatchewan, Canada)
Some principles for making of collaborative scholarly editions in digital form
June 2
Jürgen Enge, Heinz Werner Kramski, Susanne Holl (HAWK Hildesheim, Germany)
»Arme Nachlassverwalter...« Herausforderungen, Erkenntnisse und Lösungsansätze bei der Aufbereitung komplexer digitaler Datensammlungen
June 9
Daniele Salvoldi (Freie Universität Berlin, Germany)
A Historical Geographic Information System (HGIS) of Nubia based on the William J. Bankes Archive (1815-1822)
June 16
Daniel Burckhardt (HU Berlin, Germany)
Comparing Disciplinary Patterns: Gender and Social Networks in the Humanities through the Lens of Scholarly Communication
June 23
Daniel Schüller, Christian Beecks, Marwan Hassani, Jennifer Hinnell, Bela Brenger, Thomas Seidl, Irene Mittelberg (RWTH Aachen University, Germany, University of Alberta, Canada)
Similarity Measuring in 3D Motion Capture Models of Co-Speech Gesture
June 30
Federico Nanni (University of Bologna, Italy)
Reconstructing a website’s lost past - Methodological issues concerning the history of www.unibo.it
July 7
Edward Larkey (University of Maryland, USA)
Comparing Television Formats: Using Digital Tools for Cross-Cultural Analysis
July 14
Francesca Frontini, Amine Boukhaled, Jean-Gabriel Ganascia (Laboratoire d’Informatique de Paris 6, Université Pierre et Marie Curie)
Mining for characterising patterns in literature using correspondence analysis: an experiment on French novels
As announced in the Call For Papers, the dialogs will take the form of a 45 minute presentation in English, followed by 45 minutes of discussion and student participation. Due to logistic and time constraints, the 2015 dialog series will not be video-recorded or live-streamed. A summary of the talks, together with photographs and, where available, slides, will be uploaded to the GCDH/eTRAP. For this reason, presenters are encouraged, but not obligated, to prepare slides to accompany their papers. Please also consider that the €500 award for best paper will be awarded on the basis of both the quality of the paper *and* the delivery of the presentation.
Camera-ready versions of the papers must reach Gabriele Kraft at gkraft(at)gcdh(dot)de by April 30.
The papers will not be uploaded to the GCDH/eTRAP website but, as previously announced, published as a special issue of Digital Humanities Quarterly (DHQ). For this reason, papers must be submitted in an editable format (e.g. .docx or LaTeX), not as PDF files.
A small budget for travel cost reimbursements is available.
Everybody is welcome to join in.
If anyone would like to tweet about the dialogs, the Twitter hashtag of this series is #gddh15.
For any questions, do not hesitate to contact gkraft(at)gcdh(dot)de. For further information and updates, visit http://www.gcdh.de/en/events/gottingen-dialog-digital-humanities/ or http://etrap.gcdh.de/?p=633
We look forward to seeing you in Göttingen!
The GDDH Board (in alphabetical order):
Camilla Di Biase-Dyson (Georg August University Göttingen)
Marco Büchler (Göttingen Centre for Digital Humanities)
Jens Dierkes (Göttingen eResearch Alliance)
Emily Franzini (Göttingen Centre for Digital Humanities)
Greta Franzini (Göttingen Centre for Digital Humanities)
Angelo Mario Del Grosso (ILC-CNR, Pisa, Italy)
Berenike Herrmann (Georg August University Göttingen)
Péter Király (Gesellschaft für wissenschaftliche Datenverarbeitung mbH Göttingen)
Gabriele Kraft (Göttingen Centre for Digital Humanities)
Bärbel Kröger (Göttingen Academy of Sciences and Humanities)
Maria Moritz (Göttingen Centre for Digital Humanities)
Sarah Bowen Savant (Aga Khan University, London, UK)
Oliver Schmitt (Gesellschaft für wissenschaftliche Datenverarbeitung mbH Göttingen)
Sree Ganesh Thotempudi (Göttingen Centre for Digital Humanities)
Jörg Wettlaufer (Göttingen Centre for Digital Humanities & Göttingen Academy of Sciences and Humanities)
Ulrike Wuttke (Göttingen Academy of Sciences and Humanities)
This event is financially supported by the German Ministry of Education and Research (No. 01UG1509).
Seminar Programme: Göttingen Dialog in Digital Humanities (2015)
2015.04.09. 19:02 kirunews
Szólj hozzá!
Címkék: digital humanities code4lib
Federated search engine of European Poetical databases
2014.10.26. 14:53 kirunews
- A gentle proposal, v2.0 -
by Levente Seláf1 and Péter Király2
1levente.selaf (.) elte.hu, ELTE, Budapest
2peter.kiraly (.) gwdg.de, The Göttingen Society for Scientific Data Processing
INTRODUCTION
This is a technical suggestion for an implementation of a federated search engine provides the researchers a tool for querying multiple poetical databases simultaneously. This suggestion is based on the experiences of a pilot project, MegaRep (http://rpha.elte.hu/megarep/search.do), which queries two such databases Le Noveau Naetebus – Repertoire des poémes strophiques non-lyriques en langue francaise d'avant 1400 (http://nouveaunaetebus.elte.hu/) and Repertorire de la poésie hongroise ancienne (abbreviated as RPHA, http://rpha.elte.hu/), both created at Eötvös Loránd University, Budapest.
The main usage scenario of the tool is the following. The end user (the researcher) creates a query in a user interface. The user interface hides the technical, formal details and provides human readable dropdown lists, radio buttons and similar standard web user interface elements. When the user enter the form the tool creates a more-or-less language independent formal query, and sends it to the individual databases. The databases receive the query, transform it to their own query language, run the search, transform the hit list to an XML-based common format, and send it back to the caller, the federated search engine. The tool collects the results, transfroms XML to HTML, and display the merged list to the end user.
The technological background of the communication is based on the OpenSearch protocol. It is a widely accepted and used industrial standard, among others the internet browsers use it to communicate with custom search engines. You can read more at http://www.opensearch.org/. The standard is pretty straightforward, we should send a specific URL format to the server, which sends back a hit list in Atom RSS format.
THE FORMAT OF THE REQUEST URL
The simplicity of the OpenSearch is that it does not specify the format of the query itself, and because of its limitation we can not use custom URL parameters (such as &meter=hexameter), but we have to use one parameter (called searchTerms) to send our complex query. The solution is using a popular and well documented formal query language, the Lucene's query syntax.
The request URL which should be implemented by all participants:
[base URL]
?searchTerms=[query string]
&startIndex=[the index of first hit (default is 1)]
You can find the details of Lucene's query syntax here: http://lucene.apache.org/java/2_4_1/queryparsersyntax.html
This proposal suggest to implement only a limited set of the whole grammar, namely:
-
simple field-value pair
[field]:[value]
meaning: the record have field field with value as its value
SQL equivalent: field = "value" -
boolean AND, OR, NOT between field-value pairs
[field1]:[value1] AND [field2]:[value2]
meaning: the record have field1 field with value1 as its value, and another field2 field with value2 as its value
SQL equivalent: field1 = "value1" AND field2 = "value2" -
boolean AND, OR, NOT within one field
[field]:([value1] AND [value2])
meaning: the record have field field with both value1 and value2 as its value
SQL equivalent: field IN ("value1", "value2")
All these is about the formal structure of the query, but we have to define a semantical structure; an initial set of fields, and possible values as a kind of common vocabulary for the concepts described in poetic databases.
VOCABULARY OF THE POETIC CONCEPTS
We defined an initial structure. This can be extended in a later phase of the project. We tried to find those concepts which are common in the databases used in our pilot. In the design of the vocabulary we had two rules: 1) it should be language agnostic where it is possible, so where we applied categories, we denoted them by numerical values; 2) it can be extendable later. We have a two level hierarchy: some elements has qualifiers, for example: we can make distinctions between subcategories of Graeco-Roman metrical versifications.
In the tables the header contain the field names. In the body of the table the first or first two columns contain the possible values, the last column contains the meaning of the field value.
Metrics
| meter | meter_qualifier | |
| 01 | Graeco-Roman Metrical Versification | |
| 01-01-01 | hexameter – one verse | |
| 01-01-02 | hexameter – several verses | |
| 01-02-01 | distich – one | |
| 01-02-02 | distichs – several | |
| 01-03 | Graeco-Roman metrical poetry (classical meter, different from hexameter or pentameter) | |
| 01-04 | Graeco-Roman metrical versification – new meters without classical antecedents | |
| 02 | syllabic | |
| 03 | tendency to be syllabic | |
| 04 | tonic | |
| 05 | each word is a foot | |
| 06 | free verse | |
| 07 | syllabo-tonic | |
| 07-01 | German or English syllabo-tonic versification | |
| 07-02 | Graeco-Roman Metrical Versification combined with stricte syllabism | |
| 08 | Mixed Compositions (different parts of the text in different metrical systems) |
Examples:
?searchTerms=meter:02&startIndex=1
?searchTerms=meter:01 AND meter_qualifier:01-01 &startIndex=1
Segments
| segmentation | segmentation_qualifier | |
| 01 | strophic – more than one stanza | |
|
01 |
isostrophic | |
|
02 |
heterostrophic | |
| 02 | strophic – one strophe | |
| 03 | rhyming couplets | |
| 04 | laisses | |
| 05 | rimes couées, serventese | |
| 06 | terza rima |
Examples:
?searchTerms=segmentation:01&startIndex=1
?searchTerms=segmentation:01 AND segmentation_qualifier:02 &startIndex=1
Rhymes
| rhyme | rhyme_qualifier | |
| 01 | No end-rhymes | |
| 01 | alliterating, non-rhyming | |
| 02 | non-alliterating, non-rhyming | |
| 02 | rhyming | |
| 03 | assonanced | |
| 04 | word-refrain rhyming |
Examples:
?searchTerms=rhyme:01&startIndex=1
?searchTerms=rhyme:01 AND rhyme_qualifier:02 &startIndex=1
Rhyming Structure of the Stanza
The field name is rhyme_scheme. It contains a free text of rhyming structure in a scholarly accepted notation (such as AABA).
Example:
?searchTerms=rhyme_scheme:AAAB&startIndex=1
Metrical Structure (verse length)
The field name is metrical_scheme. It contains a free text of the metrical structure in a scholarly accepted notation (such as 12 16).
Example:
?searchTerms=metrical_scheme:12 16&startIndex=1
Declination of line
| declination_line | |
| 01 | rythme de vers descendant |
| 02 | rythme de vers ascendant |
| 03 | critere non applicable |
Example:
?searchTerms=declination_line:01&startIndex=1
Gonic Structure – level of the poem
| declination_strophe | |
| 01 | homogonical |
| 02 | heterogonical |
Example:
?searchTerms=declination_strophe:01&startIndex=1
Gonic Structure
The field name is declination_scheme. It contains a free text of gonic structure in a scholarly accepted notation, i.e. is one of more 'M', 'm', 'F', or 'f' character where 'M' and 'm' mean masculine rhyme, 'F' and 'f' mean feminine rhyme, and uppercase characters denote the beginning of a strophe.
Example:
?searchTerms=declination_scheme:MmMmMfMfMmMfMmMmMfMmFmMfMmMmFfMfFmMfFfMm&startIndex=1
Number of lines
The field name is number_of_lines. It contains a number denotes the number of lines.
Example:
?searchTerms=number_of_lines:8&startIndex=1
Number of strophes
The field name is number_of_strophes. It contains a number denotes the number of strophes.
Example:
?searchTerms=number_of_strophes:20&startIndex=1
Author
The field name is author. It contains a free text field denotes the author of the poem.
Example:
?searchTerms=author:Shakespeare&startIndex=1
Date
| date | date_qualifier |
| [ISO date format] | ['before'|'after'|'circa'|'between'] |
Examples:
?searchTerms=date:1321-00-00&startIndex=1 (the year 1321)
?searchTerms=date:1321-01-00&startIndex=1 (January, 1321)
?searchTerms=date:1321-01-01&startIndex=1 (1st of January, 1321)
Melody
| melody | melody_qualifier | |
| 01 | poem was sung | |
| 01 | has musical notation | |
| 02 | has no musical notation | |
| 02 | poem was not sung | |
| 03 | undecideable |
Examples:
?searchTerms=melody=02&startIndex=1
?searchTerms=melody:01&melody_qualifier:01&startIndex=1
Genre
The field name is genre. It contains the genre of the poem. It should reference to a genre classification to be elaborated.
Caesuras
The field name is caesuras. It contains the free text description of caesuras in the poem.
Language
| language | language_qualifier | Language |
| [text: ISO 639-1, 639-2, and 639-3 language codes] (repeatable) | one language | |
| 01 | sporadic bilinguism | |
| 02 | change language by verses | |
| 03 | change language by strophes | |
| 04 | the refrain and body of the strophe are in different languages |
Interstrophical relations – level of rhymes
| interstrophical_relations_level1 | |
| 01 | coblas singulars |
| 02 | coblas unissonans |
| 03 | coblas doblas |
| 04 | coblas ternas |
| 05 | coblas alternas |
Interstrophical relations - primary level note
The field name is interstrophical_relations_level1_note. It contains the free text note related to the previous field.
Interstrophical relations - secondary level
| interstrophical_relations_level2 | |
| 01 | coblas capcaudadas |
| 02 | coblas capfinidas |
| 03 | coblas capdenals (niveau des strophes) |
| 04 | rimes constantes |
| 05 | acrostichon |
| 06 | telestichon |
| 07 | prayer with glosses |
| 08 | alphabetical poem |
| 09 | coblas retrogradadas |
| 10 | dialogue (the participants recite the strophe in alternance) |
| 11 | cantio cum auctoritate |
Interstrophical relations - secondary level note
The field name is interstrophical_relations_level2_note. It contains the free text note related to the previous field.
Refrain
| refrain | refrain_qualifier | |
| 01 | without refrain | |
| 02 | with refrain | |
| 02-01-01 | identical refrain | |
| 02-01-02 | variation at the beginning | |
| 03 | with (a joint) refrain | |
| 03-01-01 | initial refrain | |
| 03-01-02 | not initial refrain | |
| 04 | multiple refrains |
OPENSEARCH DESCRIPTOR FILE
Each OpenSearch implementor should publish its implementation via a descriptor file in order to the search engine understands the implementation details they support. The descriptor file is described with details in the OpenSearch standard. Here we show you an example, the RPHA's description file (you can access it at http://rpha.elte.hu/rpha/opensearchdescription.xml):
<?xml version="1.0" encoding="UTF-8"?>
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>RPHA Web Search</ShortName>
<LongName>RPHA Web Search</LongName>
<Description>RPHA OpenSearch interface</Description>
<Developer>Seláf Levente, Király Péter</Developer>
<Tags>rpha poems web</Tags>
<Contact>kirunews@gmail.com</Contact>
<Attribution>Creative Commons</Attribution>
<Url type="application/atom+xml"
template="http://rpha.elte.hu/rpha/openSearch.do/?searchTerms={searchTerms}&startPage={startPage?}&format=atom"/>
<Url type="application/rss+xml"
template="http://rpha.elte.hu/rpha/openSearch.do/?searchTerms={searchTerms}&startPage={startPage?}&format=rss"/>
<Url type="text/html"
template="http://rpha.elte.hu/rpha/openSearch.do/?searchTerms={searchTerms}&startPage={startPage?}"/>
<Image height="64" width="64" type="image/png">
http://example.com/websearch.png</Image>
<Image height="16" width="16" type="image/vnd.microsoft.icon">
http://example.com/websearch.ico</Image>
<Query role="example" searchTerms="cat" />
<SyndicationRight>open</SyndicationRight>
<AdultContent>false</AdultContent>
<Language>en-us</Language>
<OutputEncoding>UTF-8</OutputEncoding>
<InputEncoding>UTF-8</InputEncoding>
</OpenSearchDescription>
RESPONSE FORMAT
The base structure of the response fit to Atom RSS. In the <channel> element there are some header fields, which contains information relevant to the whole response, and a number of <item> elements, for the individual results. In the header part of the response there are some important elements:
- <totalResults>: the total number of results
- <startIndex>: count number of the first element of the returned part of hit list (important: the first element's count number is 1, and not 0)
- <itemsPerPage>: the number of records in one response
In the <item> elements the implementors should provide three elements in project specific way:
- the <title> element should contain the identifier of the repository, and the identifier of the record separated by a space character. For example: <title>RPHA 0373</title>
- the <link> element should contain the URL of the record
- the <description> element should make use of fields defined inside the project's own namepsace (which is http://www.megarep.org in the sample implementation). The field are the same what we use in the query term.
An example:
<?xml version="1.0" encoding="UTF-8"?>
<!-- application/rss+xml -->
<rss version="2.0" xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>RPHA results</title>
<link>http://rpha.elte.hu/rpha/openSearch.do?language:lat</link>
<description>RPHA results</description>
<opensearch:totalResults>16</opensearch:totalResults>
<opensearch:startIndex>1</opensearch:startIndex>
<opensearch:itemsPerPage>10</opensearch:itemsPerPage>
<atom:link rel="search" type="application/opensearchdescription+xml" href="http://rpha.elte.hu/rpha/opensearchdescription.xml"/>
<opensearch:Query role="request" searchTerms="language:lat" startPage="1" />
<item>
<title>RPHA 0373</title>
<link>http://rpha.elte.hu/rpha/id/0373</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="0373">
<mr:id>0373</mr:id>
<mr:incipit>Emlékezzünk, én uraim, régen lett dologról</mr:incipit>
<mr:title>Rusztán császár históriája</mr:title>
<mr:author>Drávamelléki Névtelen</mr:author>
<mr:language>la</mr:language>
<mr:date>1600</mr:date>
<mr:date_qualifier>2</mr:date_qualifier>
<mr:melody>01</mr:melody>
<mr:genre>048,049,051,057</mr:genre>
<mr:number_of_strophes>226</mr:number_of_strophes>
<mr:meter>02</mr:meter>
<mr:rhyme_scheme>AAAA</mr:rhyme_scheme>
<mr:metrical_scheme>14141414</mr:metrical_scheme>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 0381</title>
<link>http://rpha.elte.hu/rpha/id/0381</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="0381">
<mr:id>0381</mr:id>
<mr:incipit>Én lelkecském, búdosócskám, hízelkedőcském</mr:incipit>
<mr:title>Idézet</mr:title>
<mr:author>Magyari István</mr:author>
<mr:language>la</mr:language>
<mr:date>1595-1600</mr:date>
<mr:date_qualifier>6</mr:date_qualifier>
<mr:melody>02</mr:melody>
<mr:genre>001,003,025,101</mr:genre>
<mr:genre>048,050,053,061,092</mr:genre>
<mr:number_of_lines>5</mr:number_of_lines>
<mr:meter>01-04</mr:meter>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 2052</title>
<link>http://rpha.elte.hu/rpha/id/2052</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="2052">
<mr:id>2052</mr:id>
<mr:incipit>Az elefánt nagy, mégis megöletik</mr:incipit>
<mr:title>Idézet</mr:title>
<mr:author>Bornemisza Péter?</mr:author>
<mr:language>la</mr:language>
<mr:date>1578</mr:date>
<mr:date_qualifier>2</mr:date_qualifier>
<mr:melody>02</mr:melody>
<mr:genre>048,050,053,061,092</mr:genre>
<mr:number_of_strophes>1</mr:number_of_strophes>
<mr:meter>02</mr:meter>
<mr:rhyme_scheme>AAAX</mr:rhyme_scheme>
<mr:metrical_scheme>11121216</mr:metrical_scheme>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 2053</title>
<link>http://rpha.elte.hu/rpha/id/2053</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="2053">
<mr:id>2053</mr:id>
<mr:incipit>Én császár nem lennék</mr:incipit>
<mr:title>Idézet</mr:title>
<mr:author>Bornemisza Péter?</mr:author>
<mr:language>la</mr:language>
<mr:date>1578</mr:date>
<mr:date_qualifier>2</mr:date_qualifier>
<mr:melody>02</mr:melody>
<mr:genre>048,050,053,061,092</mr:genre>
<mr:number_of_strophes>2</mr:number_of_strophes>
<mr:meter>02</mr:meter>
<mr:rhyme_scheme>AAAA</mr:rhyme_scheme>
<mr:metrical_scheme>6 6 6 7</mr:metrical_scheme>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 1340</title>
<link>http://rpha.elte.hu/rpha/id/1340</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="1340">
<mr:id>1340</mr:id>
<mr:incipit>Szólok szerelem dolgáról nektek</mr:incipit>
<mr:title>Paris és Görög Ilona históriája</mr:title>
<mr:author>Lévai Névtelen</mr:author>
<mr:language>la</mr:language>
<mr:date>1570</mr:date>
<mr:date_qualifier>1</mr:date_qualifier>
<mr:melody>01</mr:melody>
<mr:genre>048,049,051,057</mr:genre>
<mr:number_of_strophes>289</mr:number_of_strophes>
<mr:number_of_strophes>290</mr:number_of_strophes>
<mr:number_of_strophes>291</mr:number_of_strophes>
<mr:meter>02</mr:meter>
<mr:rhyme_scheme>AAAA</mr:rhyme_scheme>
<mr:metrical_scheme>11111111</mr:metrical_scheme>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 2054</title>
<link>http://rpha.elte.hu/rpha/id/2054</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="2054">
<mr:id>2054</mr:id>
<mr:incipit>Bújdosó édes lelkecském</mr:incipit>
<mr:title>Idézet</mr:title>
<mr:language>la</mr:language>
<mr:date>1578</mr:date>
<mr:date_qualifier>2</mr:date_qualifier>
<mr:melody>02</mr:melody>
<mr:genre>048,050,053,061,092</mr:genre>
<mr:number_of_strophes>1</mr:number_of_strophes>
<mr:meter>02</mr:meter>
<mr:rhyme_scheme>XXAAA</mr:rhyme_scheme>
<mr:metrical_scheme>8 8 910 9</mr:metrical_scheme>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 3216</title>
<link>http://rpha.elte.hu/rpha/id/3216</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="3216">
<mr:id>3216</mr:id>
<mr:incipit>Ó, Istennek teste édesség, e világnak oltalma</mr:incipit>
<mr:title>Könyörgés a kenyér színe alatt jelenlévő Krisztushoz</mr:title>
<mr:language>la</mr:language>
<mr:date>1433</mr:date>
<mr:date_qualifier>2</mr:date_qualifier>
<mr:melody>01</mr:melody>
<mr:genre>001,003,008,102</mr:genre>
<mr:number_of_lines>5</mr:number_of_lines>
<mr:meter>01-04</mr:meter>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 3211</title>
<link>http://rpha.elte.hu/rpha/id/3211</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="3211">
<mr:id>3211</mr:id>
<mr:incipit>Krisztus feltámada menten nagy kínjából</mr:incipit>
<mr:title>Húsvéti népének</mr:title>
<mr:language>la</mr:language>
<mr:date>1401-1450</mr:date>
<mr:date_qualifier>6</mr:date_qualifier>
<mr:melody>01</mr:melody>
<mr:genre>001,003,008,200</mr:genre>
<mr:number_of_strophes>1</mr:number_of_strophes>
<mr:meter>02</mr:meter>
<mr:rhyme_scheme>XXAAX</mr:rhyme_scheme>
<mr:metrical_scheme>6 7 7 7 4</mr:metrical_scheme>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 3209</title>
<link>http://rpha.elte.hu/rpha/id/3209</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="3209">
<mr:id>3209</mr:id>
<mr:title>Jephtes históriája</mr:title>
<mr:author>Balassi Bálint</mr:author>
<mr:language>la</mr:language>
<mr:date>1589</mr:date>
<mr:date_qualifier>4</mr:date_qualifier>
<mr:melody>03</mr:melody>
<mr:genre>001,002,004,009</mr:genre>
<mr:genre>048,049,051,057</mr:genre>
<mr:number_of_strophes>0</mr:number_of_strophes>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
<item>
<title>RPHA 3202</title>
<link>http://rpha.elte.hu/rpha/id/3202</link>
<description>
<mr:record xmlns:mr="http://www.megarep.org" id="3202">
<mr:id>3202</mr:id>
<mr:incipit>Az újesztendő kezdessék tőled, Úristen</mr:incipit>
<mr:title>Naptárvers</mr:title>
<mr:language>la</mr:language>
<mr:date>1582</mr:date>
<mr:date_qualifier>2</mr:date_qualifier>
<mr:melody>02</mr:melody>
<mr:genre>048,050,053,059,074</mr:genre>
<mr:number_of_lines>24</mr:number_of_lines>
<mr:meter>01-02-01</mr:meter>
<mr:language>hu</mr:language>
</mr:record>
</description>
</item>
</channel>
</rss>
In these items you can find, that the field names are the same what we described in the vocabulary section of this paper. There are some minor differences however: the federated genre classification has not been created, so RPHA uses its own classification, and date is not full conform of the ISO date standard.
ABOUT THE PILOT IMPLEMENTATION
The MegaRep source code is available as Open Source software at http://github.org/pkiraly/megarep. The working implementation is available at http://rpha.elte.hu/megarep/search.do. The RPHA source code is also available at http://github.org/pkiraly/rpha, the OpenSearch endpoint is http://rpha.elte.hu/rpha/openSearch.do. Both implementation was writen in Java using Apache Struts 1.0 framework. The MegaRep contains translation files to English, French and Hungarian languages, so both search and record retrieval are available in all three languages.
AFTERWORDS
The background of this proposal, i.e. the services, and the data dictionary were created 5 years ago, but it was never documented other than a bunch of spreadsheet and readme files. Recently I had to find the documentations regarding to my work on RPHA, and unexpectedly I also found the Megarep's files, so I thought it's high time to create this proposal, even if I think some parts are outdated in the light of the advances of TEI and Linked Data. There is a Hungarian proverb: it is better to do it later than never. So while we don't come with an up-to-date proposal, here you can read and use this one. If you have any suggestion, please write us.
1 komment
Címkék: code4lib
194 millió munka-szintű rekord a WorldCat-ban
2014.02.28. 21:53 kirunews
Ezt a bejegyzést eredetileg a magyar könyvtárosok levelezőlistájára írtam, de talán érdekelheti a szemantikus web iránt érdeklődő nem könyvtárosokat is.
Tegnap nagy jelentősségű bejelentést tett az OCLC. A Worldcat-en belül elérhetővé tettek 194 millió munka-szintű rekordot. Bizonyára ismeretes, hogy a MARC alapvetően egy szintű, a nyomtatványra koncentráló adatmodelljével szemben az FRBR további leírási szinteket tesz lehetővé. A legfelsőbb szint a work, vagyis a munka. Ez egy könyv elméleti ideálképe, ami alapvetően a tartalmat (szerző, cím, téma) és nem a nyomtatvány fizikai tulajdonságait (kiadási adatok, külső megjelenés stb.) hordozza. Az FRBR-ben a mű és annak manifesztációja között van még egy köztes szint, az expression, ami a mű megjelenési és nyelvi változatait írja le (pl. nyomtatott könyv, színpadi mű, képregény, x nyelvi fordítás stb.) Az OCLC az eddigi 311 millió MARC, vagyis manfestációs szintű rekordból készített és publikált 194 millió mű szintű rekordot (a köztes szintről - egyelőre? - nincs szó).
A mű szintnek (és egyáltalán az FRBR-nak) nincs sztandard implementációja, több kísérlet is létezik ennek megvalósítására (például az Library of Congress új bibliográfiai keretrendszere, vagy az eXtensible Catalog RDA-n alapuló sémája). Az OCLC most egy új implementációval állt elő: a W3C keretén belül létrejött "Schema Bib Extend" közösségi csoport ajánlásait követve a schema.org bibliográfiai kiterjesztésére és a Linked Open Data alapelvekre alapoztak (bővebben egyik tavalyi levelemben írtam errő: https://listserv.niif.hu/pipermail/katalist/2013-February/028019.html). Ami azt jelenti, hogy a rekord leírása elsősorban nem szöveg-alapú, hanem egy géppel olvasható, RDF állításokat tartalmazó részgráf. Mivel ez elég absztraktul hangzik, íme egy példa a könnyebb megértés végett:
<http://worldcat.org/entity/work/id/12477503>
a schema:CreativeWork , schema:Book ;
schema:about
<http://experiment.worldcat.org/entity/work/data/12477503#Topic/fathers_and_sons>,
<http://experiment.worldcat.org/entity/work/data/12477503#Topic/philosophy_and_civilization>;
schema:creator
<http://experiment.worldcat.org/entity/work/data/12477503#Person/pirsig_robert_m>,
<http://experiment.worldcat.org/entity/work/data/12477503#Person/pirsig_robert>;
schema:name
"Zen and the art of motorcycle maintenance an inquiry into values,"@en ,
"Zen and the art of motorcycle maintenance."@en ,
"Zen and the art of motorcycle maintenance : an inquiry into values /" ,
"Zen and the art of motorcycle maintenance : an inquiry into values /"@en ,
"Zen and the art of motorcycle maintenance: an inquiry into values,"@en ;
schema:workExample
<http://www.worldcat.org/oclc/191931910> ,
<http://www.worldcat.org/oclc/13038756> .
A Linked Data (és általában az RDF) egyik előnye, hogy a szintaxis pusztán hordozója a mögöttes adatoknak, és tetszőlegesen lehet számos adatformátumba konvertálni ugyanazt az állításkészletet. A fenti példa az úgynevezett Turtle szintaxis használja, de a Worldcatban elérhető emellett az N3, JSON-LD, RDF és HTML formátum is.
Tehát fenti példában a http://worldcat.org/entity/work/id/12477503 URI-vel azonosított dologról az alábbi állításokat tettük:
- ez egy kreatív munka
- ez egy könyv
- tárgya az http://experiment.worldcat.org/entity/work/data/12477503#Topic/fathers_and_sons URI-vel azonosított dolog
- alkotója az http://experiment.worldcat.org/entity/work/data/12477503#Person/pirsig_robert_m URI-vel azonosított dolog
- angol címe: Zen and the art of motorcycle maintenance an inquiry into values
- angol címe: Zen and the art of motorcycle maintenance. ...
- manifesztációja az http://www.worldcat.org/oclc/191931910 URI-vel azonosított dolog
- manifesztációja az http://www.worldcat.org/oclc/13038756 URI-vel azonosított dolog ...
Ugyanazon „rekordban” más állításokat is megtalálunk, például:
<http://experiment.worldcat.org/entity/work/data/12477503#Person/pirsig_robert> a schema:Person ; schema:name "Pirsig, Robert." .
Ennek jelentése:
A http://experiment.worldcat.org/entity/work/data/12477503#Person/pirsig_robert URI-vel azonosított dolog
- egy személy
- neve: Pirsig, Robert.
A példa elérhetősége: http://experiment.worldcat.org/entity/work/data/12477503.html.
Az alternatív formátumokat a http://experiment.worldcat.org/entity/work/data/12477503.ttl, .nt, .jsonld, .rdf URL-eken keresztül lehet elérni.
A következő hetekben az munka szintű rekordokra mutató linkek fokozatosan beépülnek a manifesztum rekordok oldalaiba, például a Linked Data szekcióban elérhető lesz a
schema:exampleOfWork http://worldcat.org/entity/work/id/12477503
típusú állítás, és az xISBN, xOCLCnum APIkban is szépen lassan meg fog jelenni (jelenleg is el lehet érni bizonyos trükkökkel).
Az adatokat az Open Data Commons Attributions (ODC-BY, http://opendatacommons.org/licenses/by/) licensze szerint lehet újrafelhasználni, ami nagyjából a Creative Commons „Nevezd meg!” típusú licenszeinek (pl. http://creativecommons.org/licenses/by/4.0/) felel meg.
Következő lépés a személyekre vonatkozó URI-k lecserélése VIAF azonosítókra, majd a tárgyi besorolási adatok legyerélése FAST, LCSH és hasonló névterek URI-jeire. (Jut eszembe: a múlt héten a Getty Thesaurust publikálták szintén Linked Open Data formában és ugyanezen ODC-BY licensz alatt. Bővebben: http://www.getty.edu/research/tools/vocabularies/lod/).
Az fenti fejleményeket először Richard Wallis, az említett W3C munkacsoport elnöke publikálta a blogjában, és különféle levelezőlistákon máris beindult a közös gondolkodás az adatok kapcsán: http://dataliberate.com/2014/02/oclc-preview-194-million-open-bibliographic-work-descriptions/
A dolognak - számomra - nagyon sok tanulsága van:
- ma már alig van olyan nagy projekt, ami nem valamilyen újrafelhasználást elősegítő licensszel tesz közre adatokat, ami számunkra is követendő példa kell legyen
- mivel az FRBR-nek megfelelő átalakítás egy nagyon összetett és soklépcsős folyamat, az OCLC úgy ítélte meg, hogy felesleges várni a standardizálás bevezetésére, vagy arra várni, hogy az algoritmusok elérjék tökéletesség állapotát. Ugyanennek a műnek a magyar változata például nem jelenik meg a manifesztációk között. Viszont a munkát elkezdték, lehet elemezni az eredményeket és javítani az eszközökön.
- az adatmodell lényegesebb, mint a konkrét formátum. Formátumok között lehet váltani, és ha kijön a LoC új szabványa, vagy áttörést hoz valamelyik másik (például a bibExtend, vagy az FRBRoo), akkor el lehet gondolkozni a kompabilitási kérdéseken.
- a hagyományos „bibliográfiai rekord” pontos határokból állt. Egy rekord tartalmazott minden releváns dolgot. A Linked Data esetében a rekord határa nem ilyen precíz. Fenti példában az műre vonatkozó alapállítások tárgya sokszor egy, a mű határain kívül eső állításhalmaz, mivel a tárgyakat, szerzőt és egy sor más dolgot a saját helyén kezelünk. Az OCLC által egy fájlba pakolt információk önkéntes döntést tükröznek. Gondoljuk el az alábbi szituációt: a szerzőre vonatkozó állítás egy Viaf rekordra mutat, a Viaf rekorban pedig a DBPediaára (a Wikipedia LOD változatára) mutatnak. Mit tartalmazzon ezek után a bibliográfiai rekord? Hol legyen a határa a hivatkozások felgöngyölítésének? Ezt a kérdést ezután minden egyes alkalmazás esetében a készítők kell eldöntsék.
Kellemes szórakozást mindenkinek!
Szólj hozzá!
Solr query facets in Europeana
2014.02.13. 00:56 kirunews
In Europeana we use Apache Solr for searching. Our data model is called EDM (Europeana Data Model), in which a real record* has two main parts: the metadata object, containing information about an objects stored in one of the 2400 cultural heritage institutions all over Europe, and the contextual entities, which stores information about the agents, places, concepts and timespans occured in the particular metadata object. This model has almost 200 fields, and in Solr we index all of them. We also have some special fields for facets, and we have some aggregated fields, which aggregates other fields, such as "who" field contains the metadata object's dc:creator, and dc:contributor, and the agent object's skos:prefLabel, skos:altLabel, and foaf:name fields, in order to provide the user a singe field for searching for personal names. For more information please consult our EDM and the Europeana API documentations.
One of Europeana's important aim is to make the rights statements of records clear and straightforward. You can imagine, that the 2400 partners have different approaches for licencing their objects, and right now in the database we have 60+ different licence types, in other words the RIGHTS facet has 60+ individual values. Some of them are language or version variations of the same CC licence. It turned out, that most of the users don't want to select from that range of options. And the thing is, that we can categorize these rights statements under 3 main categories:
- freely resuable with attribution (CC0, CC BY, CC BY SA)
- resable with some restrictions (CC BY NC, CC BY NC SA, CC BY NC ND, CC BY ND, OOC NC)
- reusable only with permissions (licences of the Europeana Rights Framework)
What wanted to achive is to form a new facet from these options, but the most straighforward solution, i. e. to create a new field in Solr were not an easily implementable option, because it would require a full reindexing (it would be another blog entry which explains why that was not possible), so we have to search for another solution. To count the numbers belongs to the individual rights statements in the RIGHTS facet would work, but that's only good for displaying, and it doesn't cover the problem of user interaction. To use the RIGHTS field for search turn out to be risky, because it interferes with the RIGHTS facet, so that did not worked either. Finally we come up with a fake facet, which has two sides: one on the display side, and one on the search side.
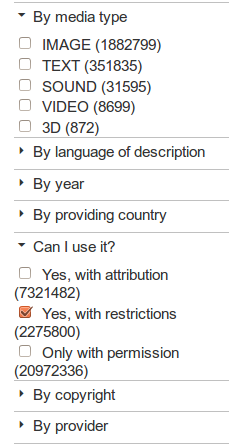
Facets including the new reusability (”Can I use it?”) facet in Europeana.eu
To count the numbers we use a special Solr facet type: query facet. It is a simple, and at the same time a powerful solution. It doesn't gives you a list of existing field values with a number (which tells you how many records has those term given the main queries) as a normal facet. In the query facet the input is a query, and the returning value is a number, which tells you how many records fit the combination of the main query, and the query specified in the facet's parameter. Since we don't need to know the list of items in the categories, that's enough for us. We defined three queries:
- RIGHTS:("CC0" OR "CC BY" OR "CC BY SA")
- RIGHTS:("CC BY NC" OR "CC BY NC SA" OR "CC BY NC ND" OR "CC BY ND" OR "OOC NC")
- RIGHTS:(NOT(
"CC0" OR "CC BY" OR "CC BY SA"
OR "CC BY NC" OR "CC BY NC SA" OR "CC BY NC ND" OR "CC BY ND" OR "OOC NC"))
In reallity we use URLs, and not string literals in the database, but the logic is the same. At the end of the blog entry I'll show you the real queries as well. There is a not well known gem in Solr: you can tag your parameters, and those tag will be in the return value. There are some tags, which has predefined meanings, but you can also add custom tags, which operationally will be ignored by Solr, so they won't affect the search itself. We use two attibute in our tag, id and ex:
&facet.query={!id=REUSABILITY:restricted ex=REUSABILITY}
RIGHTS:("CC0" OR "CC BY" OR "CC BY SA")
- ex - this is a standard tag, and stands for excluding. It means, that this query will exclude the filter tagged as REUSABILITY. This makes is possible, that when the user filters one of these 3 categories, he can see the numbers for all of them correctly.
- id - a custom tag, we use it as an identifier. It helps us to identify the query when we retrieve the result. It is more easy to find it than the quite complicated Solr query. With a simple regex we can parse the query facets in the response and link the numbers to what it belongs to.
When the user selects an item in this reusability facet, the same query runs, but now as a filter. It effects the whole result set: the number of records, and the real facets. Its format is something like that:
&fq={!tag=REUSABILITY}RIGHTS:("CC0" OR "CC BY" OR "CC BY SA")
- tag has the same role as id in the query facet. (The difference is that it is a standard Solr tag, and id is our custom solution. Unfortunatelly query facet doesn't support tag attribute, so we have to find a custom one.) We identify here this filter, and this filter will be ignored by those queries, which refers to this by the ex attribute.
All these Solr parameters runs on the background. On the Europeana portal we use a fake facet called ”REUSABILITY”, and we use it in our filtering parameter (&qf) as REUSABILITY:open, or REUSABILITY:restricted or REUSABILITY:permission. It is a shortcut for the lengthy query. We keep the interface (and the URL) clean. In the API we introduced the ”reusability” parameter with the same options as in the portal: "open", "restricted" and "permission" denotate the above mentioned categories:
http://europeana.eu/api/v2/search.json?wskey=[YOUR API KEY]&query=*:*&reusability=open
For those who interested, here is a real Solr query (slightly formatted for the sake of readability)
q=*:*
&fq={!tag=REUSABILITY}RIGHTS:(
http\:\/\/creativecommons.org\/licenses\/by-nc\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc-sa\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc-nd\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nd\/*
OR http\:\/\/www.europeana.eu\/rights\/out-of-copyright-non-commercial\/*)
&rows=12
&start=0
&sort=score desc
&timeAllowed=30000
&facet.mincount=1
&facet=true
&facet.field=UGC
&facet.field=LANGUAGE
&facet.field=TYPE
&facet.field=YEAR
&facet.field=PROVIDER
&facet.field=DATA_PROVIDER
&facet.field=COUNTRY
&facet.field=RIGHTS
&facet.limit=750
&facet.query={!id=REUSABILITY:open ex=REUSABILITY}RIGHTS:(
http\:\/\/creativecommons.org\/publicdomain\/mark\/*
OR http\:\/\/creativecommons.org\/publicdomain\/zero\/1.0\/*
OR http\:\/\/creativecommons.org\/licenses\/by\/*
OR http\:\/\/creativecommons.org\/licenses\/by-sa\/*)
&facet.query={!id=REUSABILITY:restricted ex=REUSABILITY}RIGHTS:(
http\:\/\/creativecommons.org\/licenses\/by-nc\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc-sa\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc-nd\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nd\/*
OR http\:\/\/www.europeana.eu\/rights\/out-of-copyright-non-commercial\/*)
&facet.query={!id=REUSABILITY:permission ex=REUSABILITY}RIGHTS:(
NOT(
http\:\/\/creativecommons.org\/publicdomain\/mark\/*
OR http\:\/\/creativecommons.org\/publicdomain\/zero\/1.0\/*
OR http\:\/\/creativecommons.org\/licenses\/by\/*
OR http\:\/\/creativecommons.org\/licenses\/by-sa\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc-sa\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nc-nd\/*
OR http\:\/\/creativecommons.org\/licenses\/by-nd\/*
OR http\:\/\/www.europeana.eu\/rights\/out-of-copyright-non-commercial\/*))
See it in action at Europeana.eu.
Notes
* Strictly speaking the EDM is based on linked data paradigm, so we don't have records the same ways as in a relational database. This is rather a named graph, but that's too technical, and we refer it as ”record” or ”object”.
Szólj hozzá!
Címkék: europeana solr code4lib #AllezCulture
Europeana in Ubuntu 13.10
2013.10.03. 22:42 kirunews
Smart Scopes is one of the novel features of the new Ubuntu (13.10 a.k.a. Saucy Salamander, which will be released in October 17th). Unity Dash has been the place in Ubuntu where you can find applications, files, settings, music etc. So far it searches among things belonging to your computer, or one of Ubuntu's own services (such as the software repositories, music store). The new version introduces the "smart scopes" wich extends the search with 100 external sources. The sources are usually the most popular web services, just like Amazon, Google Drive, Picassa, Flickr, Facebook, devianArt, Wikipedia, Yahoo! just to mention a few. Ubuntu sends the query the user entered to the selected sources via the services REST APIs through Ubuntu's own API, and returns back the result in a unified format. The user can enable/disable each sources either in an ad hoc mode during search (it works as a higher level faceted search), or she can set a default behaviour (whether a general search would cover the given source). The sources are organized into categories (as social, reference, music, recipies, info etc. - these are the scopes), and behind the whole process there is a dedicated search server, called Smart Scopes Server, which merges the results comming from different sources, applies a relevancy ranking algorithm, and collects anonymous metrics. The "smartness" thing is that the server collects what the users clicked on, and improve the sort order accordingly.
The big thing for myself as a Europeana API developer is that Europeana is one of the 100 sources, and this is the first time that an Operating System contains my own handwork. It is a big thing, that Ubuntu developers thinks, that our service is in the Top 100.
The search process is pretty stratightforward. If you enter your term into the big search box, and you can select Europeana results inside the Reference scope. For the first time you have to play a bit with the categories, because by default each sources are turned on, and from the big chunk of result list it is not easy to tell which item comes from where. But with the categories on the right side (which comes when you click on "Filter results" link near the search box), you can filter out those items you don't need. As mentioned before, yoou can set default behaviours at the Applications tab (next to Home) with selecting Search plugins. (The termonology is not quite clear in every case, the name the same feature as dash plugins elsewhere.)
It is possible to search only for Europeana records, using the "europeana:" prefix, such as "europeana:hrabal".
Right now the object page (what you get when you click on an item) is rather minimalistic, I hope, that it will be richer later. You can see the title, an object image, and the data provider's name (Europeana is a big data collection of 2200+ European libraries, museums and archival institutions, and each object has its provenience. We are very proud of them, and the data provider's name is transparent in all Europeana services.)
And finally if you click on the View button, it redirects you to the object page at Europeana.eu.
The URL - as every URL referenced in Europeana API - contains an utm campaign code, which makes us possible to track the usage generated by Ubuntu users. We are very curious about the results.
If you are interested, would like to send feedback to the developers, or you are just curious about the source code here is the project page at launchpad.net: https://launchpad.net/unity-scope-europeana. You can find a couple of video tutorials about the Smart Scopes at YouTube.
Szólj hozzá!
Címkék: unix europeana code4lib #AllezCulture
#AllezCulture - Hajrá kultúra!
2013.07.13. 21:34 kirunews
Az alábbi szöveg az Europeana Alapítvány által készített röplap (http://pro.europeana.eu/documents/858566/0/AllezCulture+leaflet) fordítása. A röplapot az #AllezCulture („Hajrá kultúra!”) kapmány keretében készítette az Europeana annak érdekében, hogy az Európai Unió költségvetésének átstrukturálása részeként tervezett, és az Europeana helyzetét meglehetősen nehézzé tevő megszorítás ellen érveljen. Az eredeti szöveg első része egy infografika, amiből csak a feliratokat fordítottam le. A fordításhoz fűzött észrevételeiért köszönettel tartozok Bánhegyi Zsoltnak.
Europeana – a támogatásra méltó ügy
Mi az Europeana?
Európa ingyenes digitális könyvtárát, múzeumát és levéltárát támogató infrastruktúra.
Honnan kerülnek be az adatok?
- Könyvtárakból
- múzeumokból
- levéltárakból
- kiadóktól
Mit csinál az Europeana?
Kik használják az Europeanát?
- Kulturális Intézetek
- Kreatív ágazatok
- Polgárok munkára, tanulásra és szórakozásra
Miért vagyunk fontosak?
- Támogatjuk a gazdasági növekedést
- Összekötjük Európát
- A kultúrát mindenki számára elérhetővé tesszük
Az Europeana a kulturális örökséget érintő változások katalizátora.
Miért?
- Mivel online hozzáférhetővé tesszük a kulturális örökséget.
- Mivel több mint 2 200, minden európai országot és a 29 európai nyelvet lefedő szervezet adatait egységesítettük.
- Mivel a kreatív ágazatok és az induló üzleti vállalkozások számára gazdag, interoperatív, szerzői jogi információkkal ellátott anyagokat biztosítunk
- Mivel minden állampolgár számára biztosítjuk, hogy digitális államolgár lehessen, függetlenül attól, hogy gazdag vagy szegény, kivételezett vagy jogfosztott.
Az Europeana képes volt a változásra amikor a kulturális örökséget érintő adatokat és az ehhez való hozzáférést nyílttá tette, és most a világ vezető intézménye a hozzáférhető digitális kultúra területén – ami üzemanyaggal fogja ellátni Európa digitális gazdaságát. Ma az Europeana segítségével bárki megnézheti az itt található 27 milió digitalizált objektumot, köztük könyveket, festményeket, filmeket és hanganyagokat.
Emeld fel a hangod az Europeana támogatásáért!
Segíts, hogy biztosíthassuk a Connecting Europe Facility alap támogatását
Három legfontosabb érvünk:
1. Az Europeana elősegíti a gazdasági növekedést
Az európai kreatív ágazatok gyorsan növekednek, gazdaságunk szempontjából egyre fontosabbak [1] és szükségük van üzemanyagra. Az Europeana ezt biztosítja. A kreatív és technológiai üzletágak, a szoftverfejlesztők, a mobil alkalmazásokat készítő mérnökök – különösen az oktatási, a turizmus és a játékfejlesztés területén – új és egyre ötletesebb módon hasznosítják újra az Europeana nyílt adatait és kódját. A kreatív partneri kapcsolatokon keresztül egy megosztott virtuális kutatási környezetet is építünk, ami jelentősen fogja csökkenteni az egyetemi és kutatóintézeti könyvtárak költségeit. Az Europeana nyíltsága ösztönzi és lehetővé teszi a benne lévő gyűjtemények kreatív újrahasznosítását, ami egyszersmind megsokszorozza azokat a lehetőségeket, ahogy az európai népek foglalkozhatnak saját örökségükkel.
Az adatok újrahasznosítási lehetőségeinek felszabadításával az Europeana az európai tartalomra támaszkodó kreatív iparágak és KKV-k számára biztosít megbízható alapanyagot, támogatva ezzel az innovációt és lehetővé téve a növekedést.
Hatásmutatók:
- Jelenleg 770 cég, vállalkozó, oktatási és kulturális intézmény vizsgálja, hogyan tudná az API-n keresztül saját szolgáltatásaiba (weboldalába, mobil alkalmazásaiba, játékaiba stb.) illeszteni az Europeana adatait. Lásd az olyan példákat, mint az inventingeurope.eu és a www.zenlan.com/collage/europeana.
- A digitális örökség munkahelyeket teremt – Magyarországon például több mint 1000 éretségizett főt vontak be a kulturális örökség digitalizálásába, amelynek eredményei majd az Europeanát gazdagítják. Az Egyesült Királyság-beli Historypin mérete számításuk szerint meg fog duplázódni a kulturális örökség nyitottabb digitális változatainak elérhetőségével.
- A rivális földrészek: Észak-Amerika (az Amerikai Digitális Közkönyvtár) és Ázsia (Koreai Szerzőijogi Bizottság) egyezményeket írtak alá az Europeana modelljének átvételéről.
- Az elmúlt öt év során az EU kezdeti 150 millió eurós beruházása 21 különböző ország minisztériumaitól származó 70 millió eurónyi kiegészítő támogatást eredményezett.
- Európa máig összesen több mint 1,2 milliárd eurót invesztált digitalizálási projektekbe. Az Europeana az egyetlen olyan platform, ami mindezt az adatmennyiséget összegyűjti és biztosítja a korlátozás nélküli használatot.
2. Az Europeana összekapcsolja Európát
A kultúrához való, mindenki számára egyenlő feltétellel biztosított demokratikus hozzáférés Európa minden közössége számára segít megérteni a múltat és érzékelni a kultúrák közti különbségeket, hasonlóságokat. Az Europeana határokon átnyúlóan hozza közel egymáshoz a népeket és nemzedékeket azáltal, hogy segít nekik megosztani az első világháborúhoz és a Vasfüggöny 1989-es lebontásához kapcsoló személyes és családi történeteiket. A történettudomány előadásmódjával együtt megjelenített, saját nyelven elmondott személyes történetek összekapcsolják az emberek múltját a tágabb európai történelemmel.
Az Europeana, ugyanúgy, ahogy a földrészen átnyúlóan egyes embereket összekapcsol, az egységesített modellen keresztül kulturális szervezeteket is összeköt. Ez azt jelenti, hogy Európa szerte minden együttműködő szervezet kulturális adatait összehangoltuk.
„Az emberek gyakran beszélnek a kulturális válaszfal megszüntetéséről és a kultúra új befogadók számára történő megnyitásáról, de nagyon kevesen állíthatják, hogy annyival járultak volna hozzá mindezekhez az erőfeszítésekhez, mint az Europeana a kulturális közjavak irányába tett lépésével.” Neelie Kroes, a Bizottság alelnöke
Hatásmutatók:
- Az Europeanaban 27 millió tárgy érhető el. Igazi soknyelvű és kultúraközi szolgáltatás, minden európai nyelven és mind a 27 EU tagországból vannak rekordok.
- Máig 50 000, az első világháborúra vonatkozó tárgy és történet gyűlt össze és több mint 2500 ember jött el családtörténeti eseményeinkre.
3. Az Europeana mindenki számára hozzáférhetővé teszi az európai kultúrát
Az európai kulturális örökség különféle módokon és helyeken való nyílttá és szabaddá tételével mindazok is, akik nem tudnak utazni, vagy nem utaznak (a fiatal, társadalmilag elszigetelt, vagy konfliktusok utáni állapotban levő közösségek) hozzáférhetnek ahhoz, amit az Europeana nyújtani tud. Nincsnek határok atekintetben, hogy ki ismerheti meg az Europeanában található kulturálisan jelentős helyeket, digitális objektumokat, műtárgyakat és történeteket. 2012-ben mind a 20 millió Europeana rekordot a Creative Commons Zero public domain licensz alatt publikáltuk – elérhetővé téve mind a kereskedelmi, mind a nem-kereskedelmi jellegű újrahasznosítást.
Weboldalunk maga reszponzív, vagyis a megjelenés alkalmazkodik a számítógépek, mobileszközök és a tabletek képességeihez.
Közösségi média csatornáink eljuttatják gyűjteményeinket azokra a helyekre, amiket az emberek online látogatnak, ezzel olyan csoportokat is elérve, akiknek valószinűleg nincs közvetlen hozzáférésük a portálhoz.
A digitális írástudás és családi programunk a nemzedékek közti együttműködésre továbbá arra ösztönöz, hogy osszuk meg egymással európai élettapasztalatainkat.
Partneri együttműködésünk a Promethean Planet-tel és az Euroclióval a tanárok számára biztosít forrásokat Európa szerte.
Hatásmutatók:
- Csatlakozunk minden nagy és reményteljes digitális csatornához, például a Wikipédiához, Facebookhoz, Tumblrhez.
- A mobil és tablet változatok használata növekszik.
- Tavaly egyetlen Editathon esemény alatt a Wikipediában hivatkozott Europeanás tartalmakat több mint egy milliószor érték el, hírlevelünket 110 000-szer nyitották meg, Facebook bejegyzéseinket átlagosan 17 ezren nézik meg.
Az Europeana által végrehajtott CC0 publikálás valójában egy olyan merész lépés, ami ‘segít galériák, könyvtárak, levéltárak és múzeumok számára követésre érdemes precedenst teremteni – másrészt segíteni fog egy kicsit közelebb kerülnünk a kulturális tartalmakat felölelő, mindenki számára szabadon használható és élvezhető digitális közjavakhoz’ Jonathan Gray, Open Knowledge Foundation.
Mit csinálna az Europeana a befektetéssel, ha megkapná?
- Kulturális örökség tekintetében a világ vezető digitális szolgáltatásaként – infrastruktúráját megerősítve, még több embert elérve – fenntartja az Europeanát.
- Kereskedelmi befektetéseket vonz.
- További audiovizuális tartalomfejlesztéssel elégíti ki a felhasználók igényeit – más tartalomtípusokhoz képest tízszer valószinűbb, hogy felhasználóink meglátogatják ezeket.
- A tartalmakat tovább igazítja a felhasználó igényekhez és érdeklődési területekhez.
- Katalizátorként működik, segítve a kulturális örökség szektorát abban, hogy szolgáltatásaikat úgy építsék és fejlesszék, hogy az megragadja az új nemzedékek figyelmét.
Milyen következményekkel jár, ha az Europeana nem kapja meg az EU támogatását a Connecting Europe Facility programon belül?
- Az Europeanán keresztül generált kereskedelmi lehetőségek kétségkívül megszűnnek, aminek további következményei is lesznek a kulturális és oktatási ágazatok gazdasági fejlődésére.
- Jelenleg az Europeana és ennek következtében maga Európa is világvezető a nyílt adatok terén – ez a globális kulturális és technológiai vezetőszerep elvész.
- Elvész a digitális szabványosítás, interoperabilitás és a szellemi jogvédelem harmonizációja terén nemcsak Európában, de az egész világon elért fejlődés.
[1] A kreatív ágazatok az EU GPD-jének 3.3%-át, és a foglalkoztatottság 3%-át teszik ki. Forrás: European Competitiveness Report 2010. (Európai versenyképességi jelentés, 2010). A kreatív ágazatok évi növekedése 7%.
1 komment
Címkék: europeana #AllezCulture
Drupal distribution development practices
2013.07.07. 14:38 kirunews
In my part time I am working on eXtensible Catalog Drupal Toolkit project. It is a next generation Open Source library* discovery interface, i. e. the end user interface of a catalog. We have three types of Drupal projects: a row of Drupal modules (about 20+ modules), a theme, and a distribution with a installation profile. All there projects are stored permanently at drupal.org's Git repository. If you want to try out the Toolkit, right now it is quite simple, because the distribution. This post is about my practices I follow when working on the development of this distribution.
The normal module/theme development is that I set up a new Drupal site, go to modules and themes, checkout the git repos, and start working. When I fix a problem, I commit it, and push back into the shared repository, so other developers can use my code. But in case of distribution development we work with a Drupal instance without Git directories inside. Our main task is this time to check whether we have issues during the installation process.
The eXtensible Catalog is quite unique in several aspects: it should handle millions of records (usually every reading material has a node and since we work with FRBR module, we have 4 other record types, so an academic library with 3 million items produces 12 million metadata records, 3 million nodes, and 3 million Solr documents). We don't use CCK and field/entity framework (we created our own solution, but that is not the topic of this entry). One of our design principles was that librarians should be able to modify (almost) every aspects of the catalog. The consequence of all these is that lots of the business logics are described in database, and behind the relatively small number of end user pages, we have dozens of admin pages - to govern the display and behaviour of the end user pages (this is the biggest difference between XC and my other project, Europeana, where the business logic is described by Java codes). If you would have to fill these admin screens by scratch, you would probably give it up before reaching the end of this huge task, so we provided default values. These default values are stored in comma separated values or XML files, and injected as a part of the installation process of the individual submodules. Some modules dependent on others, for example we have an xc_metadata module to handle metadata management, and some metadata schema modules for the RDA-like XC schema, and another one for the Dublin Core schema. When the XC schema module is installed, it calls the metadata module's API to store and register the XC schema to the system, so the order of installation is crucial in this case.
The distribution project does two things:
- with Drush make's help it selects and downloads the necessary components a library needs to setup a fully working XC Drupal instance and
- it has an installation profile, which installs these components in the right order, and sets some site-wise values, like the default theme, and the name of site. It also prepares the harvester to be able to fetch some demo data from another XC component (the Metadata Services Toolkit) with which the library can start working.
From this picture you might guess, that there are lots of things during the installation of Drupal, and these processes are triggered and orchestrated by the installation profile. However if something went wrong it is usually happens inside modules (sometimes as the result of the combination of several modules). As I said earlier in this phase of development we concentrate on the issues happens during the installation, and we enter this phase only if in the after-installation-period of the life cycle the software works perfectly (if that's not true, we have to go back to our previous development model). In this distribution-development phase we have to fix the module, then launch the installation again. But since here we lack the advantages of Git, we modify the codes in another directory, where we have Git and copy the modified versions here with rsync. I personally use Eclipse, and in that tool a new project setup is not painless, so I usually work with my code in an established directory, and copy the codes when it needs. Others prefer to fix the code in place, and sync with the repo in a different way. Either way is OK, and might work for you. Here is the script I use for syncing, and cleaning up the database:
INSTALL_WORKSPACE='/workspace/xc_installation-repo/'
MODULE_WORKSPACE='/workspace/xc-modules-repo/'
INSTALL_SITE='/var/www/xc-7.x-test-installation/profiles/xc_installation'
# clean_db.sql contains the deletion of all tables inside Drupal
mysql -u XXXXX -p xc710 < clean_db.sql
# syncing code bases
rsync -azv --exclude '.git' $INSTALL_WORKSPACE $INSTALL_SITE
rsync -azv --exclude '.git' $MODULE_WORKSPACE $INSTALL_SITE/modules/xc
It will ask your database password, deletes all the tables, and updates the code base, skiping the git-related directories. Then I go to Drupal, and launch http://localhost/xc-7.x-test-installation/install.php, select the installation profile I'd like to test (which is always my favorite one: "eXtensible Catalog Drupal Toolkit installation" ;-), and click the big button (or use Drush, and I don't need to delete the tables and use the browser for launching installation -- see the end of this post). This iteration (code change - deployment - testing) goes on untill all current issues has been solved.
Then enters another circle: making my code available, and testing whether the solution is available to others. So I commit my changes with Git, and push them into the Drupal.org repository. To build another distribution release requires a couple of steps:
- create a new release of the module/theme
- create a new tag in the repo
- create a release in the Drupal.org project page
- create a new release of the distribution
- modify the drush make file to reflect to the new module/theme version (and commit it)
- create a new tage
- create a new release in the Drupal.org project page of the distribution
While the project is not mature enough (which practically means, that we know that still there are annoying bugs) we create an alpha versions, like 7.x-1.0-alpha3. If all those bugs were killed, we can start to create release candidates such as 7.x-1.0-rc2. The tags, and so the name of releases should follow Drupal's naming conventions. I personally don't like creating distribution based on dev versions, because it is hard to tell, which state of the software we test against (dev versions are generated twice a day on Drupal.org with the current state of the defined git branch, so today's dev version is different than yesterday's dev version - if the project development are constant, and ours is so). The creation of distribution releases takes longer time than that of modules/themes. So a full circle of this process might take half an hour of boring and repetitive tasks and simple waiting. But when its done, with few commands we can test whether our development fixed the problems:
$ cd /var/www
$ drush dl xc_installation-7.x-1.0-alpha3 --drupal-project-rename=xc-7.x-test-installation
$ cd xc-7.x-test-installation
$ drush si xc_installation --db-url=mysqli://[mysql user]:[mysqlpw]@localhost/xc --site-name="eXtensible Catalog" --account-pass=admin
Then we can log in http://localhost/xc-7.x-test-installation/ as admin/admin, and check whether it works. When everything is working - not only for us, developers, but for our friends/colleagues who we asked to test the release, we can create a new release with the final name, which is 7.x-1.0 without the alpha/rc suffixes. The process is the very same, except at the end you might want to open a bottle of champaign**, since you finished a half year work.
Notes:
* library as an institution for collections of readings
** I am an abstinent, I will make my tea.
Szólj hozzá!
Címkék: drupal eXtensible Catalog code4lib
A könyvtár jövőjéről
2012.11.05. 16:54 kirunews
A könyvtár jövőjéről
Könyvtár
Szerepe
A könyvtár célja az információk eljuttatása a felhasználókhoz. Ezek az információk hordozói a jövőben egyre kisebb mértékben lesznek a könyvek. Az információszolgáltatás helye egyre kisebb mértékben a könyvtár, a könyvtári épület egyre kisebb mértékben hagyományos olvasóterem.
Az információk világa rendezett és rendezetlen adathalmazok sokasága. A könyvtár tradícionális szerepe a bizonyos formában létező adatok értelmezése és rendezése. A könyvtár ezt a kompetenciáját sikeresen ki tudhatná terjeszteni a dokumentumokró más területekre is. A könyvtártudomány metaadat-tudomány. Az árúcikkeknek, tv programoknak, jogi anyagoknak vannak metaadataik, de nincs metaadat-kezelő hagyományuk. A szemantikus web, web 3.0 ezt az igényt teszi transzparenssé, tehát a könyvtár-informatikának a maga 100 éves rendezett kutatási, oktatási és kézműves tradíciójával még van némi előnye. Azonban ami igaz a könyvtári világ egészére, csak nagyon kevés könyvtárra igaz. A könyvtári metaadatok kutatásának és ezen kutatások implementációjának élvonalához mindenkpppen fel kell zárkózni, hogy akár a jelenlegi versenytársakkal fel tudja venni az intézmény a versenyt. Ami az informatikai, implementációs szintet illeti, itt sajnos törvényszerű a folyamatos elmaradás. A megfelelő képzettségű munkatársak számára a közgyüjteményi szféra az egész világon versenyhátrányban van.
Nem tartható az az álláspont, hogy a könyvtárosnak elég olyan szinten érteni az informatikához, hogy meg tudja határozni a programozó feladatát. Nem kell mindenkinek programozóvá válnia, de a programozás és más magas szintű készségek (adatbányászat, statisztikai elemzés, webes szolgáltatások összekapcsolása stb.) alapvetőek az intézmény profiljában, vagyis intézményi szinten (és ebben minden intézménytípust bele kell értsünk) a könyvtárnak kompetensnek kell lennie ezeken a területeken, különben nem tudja kiaknázni a szakmai ismeretanyagból származó helyzeti előnyét.
Közösségi tér
A könyvtári épület egyre kevésbé az olvasás tere, és egyre inkább szolgálja azt a közösséget, aminek a része (egyetem, település stb.). A „könyvtár”: tanulószoba, konferenciahelyszín, színház, számítógépközpont, játszóház, nyilvános hang- és videóstudió stb. (itthon: bálásruhavásár). Másrészt: a könyvtár egy civilizációs eszköz, mint például a tömegközlekedés, vagy az oktatási intézmények, vagyis segít abban, hogy a társadalom ne a „mindenki harca mindenki ellen” állapotában legyen – íly módon a könyvtár (mint számos példa mutatja) az esélyteremtés, társadalmi igazságosság megteremtésének egyik eszköze.
Intézmény
Együttműködés
Országos szinten nem lehet tovább halogatni a tényleges közös katalogizálás és közös információ-szervezés bevezetését. Az OCLC példája mutatja, hogy kétségtelen hátrányait (helyi szinten a címleírási készségek csökkenése - lévén kevesebb címleíró fog dolgozni -, és a helyi címleírási hagyományok, szokások megszűnése) messze felűlmúlják az előnyei (a rekordok egységessége, a dokumentumok lefedettsége, naprakészsége, az egységességből fakadóan jobb másodlagos szolgáltotások létrejötte). A könyvtáraknak meg kell osztaniuk egymással az adataikat, mert ez anyagilag előnyös, növeli a szakmai kapcsolatokat és az itthon fájdalmasan hiányzó együttműködés ethoszát ami önmagában is példamutató lehet a társadalom számára. Dániában a könyvtárközi kölcsönzés nem csak közös adatbázison, de közös logisztikai rendszeren is alapszik.
Az együttműködés nem csak könyvtárak között érvényes elv, hanem a könyvtáron belül. Számos esetben tapasztalni a könyvtári szolgáltatásoknak a belső együttműködés elmulasztása miatti minőségcsökkenését, vagy azt, hogy eleve nem érnek el egy máskülönben kívánatos és megvalósítható nívót. Például a tájékoztató szolgálati munkatársak tárgyi tudása semmilyen módon nem épül be a katalógusba, vagy a kézirattári dokumentumok eltérő adatszervezési modelje nem termékenyíti meg az informatika munkatársainak gondolkodásmódját.
Az Egyesült Államokban úgy próbálják a költségvetési csökkentés ellenére fenntartani a szolgáltatásokat, hogy a könyvtárak adott szolgáltatásokat közösen üzemeltetnek (pl. közös adminisztráció (pl. igazgató, informatikus, könyvelő), közös kölcsönzési rendszer, és olvasójegy, közös szállítási költségek, közös vásárlás és beszerzési alkuk). Iowában lehetőség van „könyvtári körzeteket” kialakítani, melyek élnek efféle megosztott szolgáltatásokkal.[1]
Együttműködés a saját környezettel
A könyvtári marketing alapelve: ismerd meg a felhasználódat. Nincs általános recept, talán csak az az elv, hogy a könyvtári profilt az adott felhasználói közösség arculatának megfelelően kell kialakítani. Ez nem jelenti azt, hogy a könyvtár ne mehessen avantgárd módon elébe az elvárásoknak, és önmaga formálja szűkebb társadalmi örnyezetét. Néhány példa:
Egyetemi-tudományos szféra: oktatási-kutatási együttműködések, ahol a könyvtári tudás (tudományos kommunikáció, metaadatok, kiadás, szerzői jogok, megőrzés, a digitális világ ismerete) mint hozzáadott érték van jelen.[2] Több olyan sajátos interdisziplináris tudományterület alakul mostanság, ahol a könyvtár-informatikai ismeretek és valamilyen más szakterület együttes megléte szükséges a kutatáshoz, ilyen például a bölcsészeti informatika vagy a „big data” science (az óriási adathalmazok elemzése, akár tudományos, akár egyéb (közigazgatási, vagy tájékoztatási) célból. Egy 2011 március végi szakértői kerekasztal-megbeszélésen így fogalmaztak: „néhány helyen, például az Egyesült Királyságban egy új »hibrid mesterség« kialakulását figyelhetjük meg, mely négy kulcsszerepet fed át: a számítógép szakértőét, egy szaktudósét vagy szakmérnökét, egy információtechnológusét és a könyvtártudósét.”[3] Az Egyesült Államokban az utóbbi egy-másfél évben sorra alakultak ilyen tudományos műhelyek, melyek a könyvtártudomány szervezési ismereteit és gyakorlatát valamint valamely tudományterület szakismeretét próbálják hasznosítani.
A Raiffeisen bank volt vezérigazgatója szerint a strukturális munkanélküliség okai: „a szakképzettség, a nyelvtudás, a számítógépes ismeretek, a mobilitás alacsony szintje”.[4] A könyvtár kisebb vagy nagyobb arányban, de mind a négy felsorolt területen kulcsfontosságú, és meglehetősen hatékony háttérintézmény lehet. Különösen kihangsúlyozandó a mobilitás, hiszen a könyvtárat nem terhelik azok a kölcsönös együttéléssel járó társadalmi feszültségek, amelyekkel például a cigány és magyar gyerekek iskolai oktatása kapcsán találkozunk, hiszen a könyvtári tanulás elsősorban egyéni tevékenység (senkit sem zavar, ha a másik lassabban vagy mást olvas).
A philadelphiai Free Library költséghatékonysági elemzése számos együttműködési programot ismertet: könyvtár-rendőrség, könyvtár-iskola, könyvtár-egyéb oktatási intézmény, könyvtár-szociális intézmények, könyvtár-munkaügyi központok mind-mind azt a célt szolgálják, hogy a könyvtár minél hatékonyabban és láthatóbban legyen jelen a „társadalom szövetében”, minél inkább aknázza ki azt a szellemi erőforrást, amiért a közösség azt létrehozta.
A könyvtár mint az információ tálalásának szakértője hasznos segítséget nyújt intézmények, cégek saját szolgáltatásukra irányuló tájékoztató tevékenységében. Jelenleg a „Meghívó: TÁMOP-3.2.4-08/1/KMR-2009-0020” Katalist levél tárgysor és a „a hét első munkanapját megelőző munkaszüneti nap” MÁV-magyar időpontmeghatározás, valamint az „és reményeink szerint hamarosan kinevezésre kerülnek a felelős személyek” típusú hivatali zsargon ugyanannak a gondolkodásmódnak a következménye, amely egyáltalán nem gondolkodik azok fejével, akiknek az üzenet szól, így az adatból nem vállik információ, vagyis az ilyen fajta tájékoztatás tulajdonképpen felesleges, alacson hatékonyságú. A könyvtár lehetne a szabatos, pontos, de érthető tájékoztatás szakértője.
Néhány extrém(nek tűnő) példa egyéb közösségi célú együttműködésre.
Környezetvédelem: A Calgary közkönyvtár[5] egyik fókusza a környezetvédelem népszerűsítése, segítése. Néhány a számos programjuk közül: utcai környezetvédelmi kampány, elültethető olvasójegy[6], egy könyv + sok olvasó = zöld gondolat (egy olvasó évi 14 ezer fát véd meg), nyári öko-olvasótábor, résztvétel zöld eseményekben (föld órája, víz napja), családi programok (magvas vasárnap, „öko gyerekek” (gyermeknevelési tanácsadás), bicikli-népszerűsítés), szelektív szemétgyűjtés.
Zöldséget a könyvtárból: a baltomore-i városi egyészségügyi osztály azokon a településrészeken, ahol a legnehezebb elérni a friss, egészséges zöldségféléket (tömegközlekedés hiánya, szegénység) és ahol legrosszabbak az étkezéssel összefüggő egészségügyi mutatók elindította a Virtuális Szupermarket Programot [7] azzal a jelszóval, hogy „Zöldséget rendelj a könyvtárban”. Heti egyszer a könyvtárakban (és iskolákban) lehet rendelést leadni, másnap oda szállítják ki – ingyenesen.
Művészeti projektek: A párizsi Raspouteam az 1871-es párizsi Kommün napjait és helyszíneit eleveníti fel könyvtári dokumentumok segítségével[8]. Minden nap az eredeti helyszíneken helyeznek el installációkat (többnyire korabeli újságok illusztárciós anyagának az átdolgozásait) és egy-egy QR kódot. A kód elvezet egy weboldalhoz, ahol az esemény bővebb leírását adják korabeli napilapok és egyéb források segítségével.
Magyar viszonyok között nagyon is járhatónak tartanék egy olyan szolgáltatást, amikor a könyvtár tartaná karban a helyi közhasznú információszolgáltatásokat (vagy adna ebben tanácsot), amit jelenleg tipikusan az önkormányzati „portálok” nagyon alacsony színvonalon látnak el. A helyi lakosság ilyen köznapi kérdésekre kaphatna választ: melyik most az ügyeletes gyógyszertár? meddig van nyitva a bolt? mi lesz a mai menü a kifőzdében? mikor kezdődik az esti az edzés? mikor indul a busz A-ból B-be? A könyvtár a szolgáltatás kapcsán személyes kapcsolatba kerülne az információ szolgátatókkal, a közösség számára egy (végre) használható szolgáltatást nyújthatna, és még az önkormányzat is ráébredne, hogy a könyvtár hasznos dolog.
Könyvtári adat
A közpénzből létrehozott könyvtári adat közkincs. Az adatok megnyitása nem csak a kritikára, hanem a jobbításra is ösztönöz. A 2.0-ás alkalmazások bebizonyították, hogy a megnyitott adattárak sokszor teljesen váratlan, a társadalom számára hasznos felfedezésekhez, újításokhoz vezetnek. A könyvtári adat tehát egyre kevésbé saját, és egyre inkább közösségi tulajdon. Az utóbbi időben nagyon sok nemzetközi szervezet szorgalmazza a közgyűjteményi adatok speciális licenszelését (pl. CC0, vagy ehhez hasonló jogi nyilatkozat alatt), amivel a gyűjtemény bárki számára, bármilyen felhasználási céllal rendelkezésre bocsátja a megtermelt adatokat. Ez a licenszelési politika jogi és technológiai szempontból is erősiti mind a könyvtárközi együttműködéseket, mind a könyvtár-társadalom kapcsolatát. A könyvtári/közgyűjteményi adatokkal szemben speciális elvárás a hosszú távú megőrzés szempontjainak érvényesítése. Az interneten található sokszor efemer, gyorsan eltűnő adatok világában ez a fajta hozzáállás további bizalmat kelt.
Informatika
A könyvtári informatikai rendszer nem lehet sziget, hanem nyílt szabványokon alapuló, együttműködésre képes rendszernek kell lennie. Amennyire lehet, támogatni kell a nyílt forráskódú fejlesztéseket, mivel ez az alapja annak, hogy a könyvtár ne legyen kötve a szolgáltatók magánérdekeihez. A trendek szerint a rutin jellegű rendszer-karbantartási feladatokat ki kell szervezni (pl. informatikai felhő), és arra kell koncentrálni, ami a könyvtári informatika saját kompetenciája: könyvtári fejlesztés, könyvtári-információszervezési tudást igénylő szolgáltatások.
Igazgatás
Bent
A döntéseknek transzparenseknek, indokoltnak, számonkérhetőnek, hatásuknak pedig ellenőrzöttnek kell lenniük. Bizonyos tevékenységek mérhetőek, ezeket mérni kell, az eredmények alakpján pedig módosítani az intzéményi igazgatást. Az könyvtári vezetők nem a könyvtáros ellen vannak, hanem azért, hogy segítsék, ösztönözzék a kézműves munkáját. A könyvtári vezető nem a legfőbb döntnök, nem a kijáróember, nem tudós professzor, hanem mindenekelőtt az embereket együttműködésre hangoló, a konfliktusokat, akadályokat elhárító menedzser.
Mivel a könyvtár szerepe változik, és környezete változó környezet, a könyvtár is változó szervezet, aminek egyik hatása, hogy a könyvtár sikerességéhez szükséges mukakörök is változnak.
Kint
A könyvtárosok összessége: civil szervezet, aminek lennie kell érdekérvényesítő képességnek is. Ehhez transzparenciára és a kamarillapolitizálással való szakításra van szükség. Ahhoz, hgy a könyvtár sikert érjen el, napról-napra be kell bizonyítania a fenntartóinak, hogy szükség van rá, ezért meg kell talánia azokat a helyi problémákat, melyekben az intézményi készségek segítséget nyújtanak. Az angolszász könyvtári költségvetési elvonások szerencsésen megmutatták azokat a társadalmi problémákat, melyekben a könyvtár – néhol túllépve a dokumentum- vagy metaadatezelés témakörén – sikeresnek és előremutatónak bizonyult: a társadalmi szegregáció csökkentése oktatás, játék és kézművesfoglalkozások által, tanácsadás munkanélkülieknek, üzleti tanácsadás, családkutatás, konfliktus-mediálás, informatikai segítség és mások.
A könyvtár nem passzív szemlélője a világnak, hanem alakítója a folyamatoknak. Nem pusztán végrehajtója egy intézkedésnek, de részt vesz annak előkészítésében és szükség esetén igénybe veszi a közösség támogatását a döntések megváltoztatásához. Egy konkrét példát kiemelve: tudták-e vajon azok a politikai döntéshozók, akik a szerzői jog hatályát kiterjesztették, hogy ezzel egyúttal társadalom számára feltehetőleg nagyobb hasznot hajto könyvtári szolgáltatások alól húzzák ki a talajt, és a könyvtári társadalom tett-e lépéseket annak érdekében, hogy erről mind a döntéshozók, mind a döntéshozókat delegáló társadalom értesüljön? A feladat adott: ilyen és ehhez hasonló ügyekben párbeszédet kell kezdeményezni.
Könyvtáros
Vita, párbeszéd
A könyvtár nyitott szervezet. Folytonos párbeszédre kell törekedni a szakmán belül, más rokonszakmákkal (elsősorban a közgyűjteményekkel és az oktatással), valamint és legelsősorban a felhasználókkal. Meg kell állapodni a vitakultúrát elősegítő két pontban: 1) nem a személyemet, hanem a véleményemet kérdőjelezik meg (Weöres: „Nem a kakas, az ember mondja, hogy kukurikú”) 2) ne vélekedések, hanem tények alapján vitatkozzunk. A könyvtáros aktív vitapartner.
A magyar könyvtári szakmának minél szélesebb sávban kell kilépnie a nemzetközi színtérre. A kommunikációs lehetőségek teljesen egyformák itthon és nyugaton. Bár az utazási lehetőségek szűkösek, virtuálisan be lehet és kell kapcsolódni a nagy vitákba (Linked Data, metaadat-szabványok, e-könyvek, digitális megőrzés stb.), és átültetni vagy kialakítani az optimális gyakorlatot. Az Unióban számos olyan együttműködési forma létezik, melyek módot adnak a szakmai párbeszédre, a tanulásra, publikációra, az európai döntéshozókkal folytatott megbeszélésekre, és a közös munkálkodásra.
Tanulás
A könyvtárosi tudásnak jelen szempontból alapvetően két komponense van. Az első egy általános absztrahálási képesség, mely képes az adatok értelmezésére, a lényeges és lényegtelen megkülönböztetésére, különféle szempontok alapján történő elemzésére (metaadatolás vagy hagyományosabban bibliográfiai leírás) és magasabb, esetleg univerzális szempontok alapján történő tartalmi kategorizálásra (tárgyszó, tezaurusz, ontológia). A második pedig a különféle, gyakorta változó eszközök ismerete.
Az erőteljes informatikai jelleg miatt, és az informatika természete miatt folytonos tanulásra van szükség. Nem csak szervezett és az intézmény irányából ösztönzött, hanem a szakma érdeklődéshez kapcsolódó önálló ismeretszerzésre. A „tanulnivaló” végtelen, még az olyan, távolról talán mozdulatlannak tetsző területeken, mint a kodikológiai bibliográfiai leírás is rengeteg változás van, amiket meg kell ismerni, és amit implementálni kell a napi munkában.
Tehetségkutatás
A könyvtári szervezet segít abban, hogy a tehetséges fiatalok (és öregek) megvalósíthassák előremutató elképzeléseiket. A pozitív, befogadói attitűd visszahat, később ők fogják mentorálni az újakat, ezáltal biztosítva a könyvtár jövőjét. Ehhez persze rugalmas munkaszervezésre, és emberi-erőforrásgazdálkodásra van szükség: a teljesítmény folyamatos értékelésére, a beosztottak egyéni szakmai céljai kitűzésére, megvitatására, és az elért (akár negatív) eredmények felülvizsgálatára. Ha feltárjuk a kudarcok és sikerek valódi okát, ezzel a tudással korrigálhatjuk a rendszert. Mindig vannak és lesznek innovatív homo novusok, ne hagyjuk őket átcsábulni más területekre.
Olvasó, felhasználó
A nem-olvasó
Régen a könyvtárakat talán kizárólag olyanok látogatták, akik maguk is olvasók voltak, legalábbis olvasni akartak. A jövőben egyre több olyan felhasználó lesz, akit a könyvtárlátogatásában semmi sem köt az olvasás aktusához. A könyvtár és a könyvtáros számára közvetítő szerepet játszik: a tér, ahol tanulhat, beszélgethet, játszhat, filmet nézhet, vagy a házi eszközöknél jobb minőségben elkészíthet egy videót, biciklit kölcsönözhet stb. Esetleg bizonyos esetben konzultál a könyvtárossal is. Lehet, hogy esetleg igénybe fogja venni a hagyományos könyvtári szolgáltatásokat, és talán nagyobb esély van erre, mint azok esetében, akik még a könyvtár küszöbét sem lépik át, de nem biztos. Az biztos, hogy ennek a térnek a szerepe felértékelődik, és mivel ezt a teret könyvtárnak hívják, magának könyvtárnak a szerepe, társadalmi támogatottsága is felértékelődik. Itthon különösen fontos, hogy míg a hagyományos közművelődési színterek (művelődési és ifjúsági házak, -központok, mozik) jóformán teljesen eltűntek, a könyvtárak még fennmaradtak.
Az írni-olvasni nem tudó
Speciális látogatót jelent az a kör, melynek tagjai azért járnak a könyvtárba, hogy elsajátítsák az olvasás, írás és értelmezés képességét. Nagy amerikai közkönyvtárak tartanak kurzusokat tényleges analfabétáknak. Vannak szolgáltatások, melyek az álláshirdetések értelmezésében segítenek. A legkiválóbb egyetemek könyvtárai biztosítanak helyet elemi és haladó írás kurzusoknak („Hogyan írjunk szakdolgozatot?”, „Hogyan írjunk regényt?”). A könyvtár itt hely, szervező, megfelelő képesítések megléte esetén oktató, tanácsadó.
Az olvasó
Nem lehet nem észrevenni, hogy létezik egy szinergia a könyvtár – könyvkiadó – könyvesbolt – olvasó négyszög körül. Az olvasók egy köre szeret saját könyvtári katalógust építeni, és szereti tartalmi metaadatokkal ellátni a könyveit, a könyvtári metaadat-szabványok és az elektronikus katalógusok egyre inkább teret engednek ezen adatok integrálásának, a címleírásnak a könyvesboltokban és a könyvtárakban kell lennie egy közös metszetének (a könyvebolti ideális esetben deriváltja a könyvtárinak), a digitális könyvtár rengeteg könyvkiadói funkciót tartalmaz, az elektronikus folyóiratokat tipikus módon közvetlenül a kiadó publikálja a könyvtári rendszerbe integráltan.
Összefoglalás
Elgondolásom szerint a könyvtári rendszert abban az irányban kell erősíteni, hogy elmozduljon egy általános információ-szervezési, és információ-közvetítő szerep felé. Ehhez meg kell találni azokat a módszereket, melyek segítenek az olvasás-központú ismeretszerzés terén szerzett tapasztalatokat áttranszponálni helyben megtalált (oktatási, tudományos, szakmai, közszolgálati) feladatok megoldásának támogatásába. A jelenleginél sokkal nagyobb hangsúlya lesz az informatikai ismereteknek és a nemzetközi kapcsolatoknak. A stratégiai irányváltáshoz elengedhetetlenül szükségesnek látom a könyvtári irányítási és kommunikációs gyakorlat megújulását is.
Jegyzetek
[1] Jason Pulliam – Sara Sleyster: Can libraries save by sharing services? (http://www.desmoinesregister.com/article/20110405/NEWS/104050366/-1/GETPUBLISHED03/Can-libraries-save-by-sharing-services-)
[2] Digital Humanities Center Funded at Emory. http://shared.web.emory.edu/emory/news/releases/2011/03/digital-humanities-center-funded-at-emory_007.html
[3] Erwin Gianchandini: National Science Board Talks „Big Data”. http://www.cccblog.org/2011/03/29/national-science-board-talks-big-data/
[4] Felcsuti Péter – Felcsuti Balázs: Vakvágányon (http://index.hu/gazdasag/penzbeszel/2011/04/06/vakvaganyon/)
[5] http://calgarypubliclibrary.com
[6] http://stationery.blogs.com/.a/6a00d83453a95e69e200e552b0d5da8834-pi
[7] http://www.baltimorehealth.org/virtualsupermarket.html
[8] http://www.raspouteam.org/1871
Megjegyzés
A tanulmány eredetileg egy Networkshop-vita indítója volt, jelen, átdolgozott formájában megjelent a 3K 2012 októberi számban.
Szólj hozzá!
Két hónap
2012.08.13. 21:39 kirunews
Ha gyalog megyek be a könyvtárba néha megfogalmazok magamban mondatokat arról, amit jelenleg átélek, de amikor gép közelében vagyok általában a munkámra koncentrálok, vagy a családdal tartom a kapcsolatot, vagy ügyintézek (ami hollandul nem mindig egyszerű dolog, tekintve, hogy nem tudok hollandul). Most Kurucz István (nevergone.hu) biztatására elkezdek néhány dolgot leírni,
KEZDET. Május 7-én jöttem ki Hágába, 14-én kezdtem el dolgozni ez európai digitális könyvtárban (europeana.eu), mint "portal backend developer" (a hivatalos megnevezést és vele a munkaköri leírásomat csak az egy hónapos próbaidő leteltével kaptam). Az első heti feladat adott volt: lakást kellett találnom. A tervem az volt, hogy két hónapra kibérelek egy garzont, vagy egy szobát, közben tudok keresni egy, a teljes családnak megfelelő nagyobb lakást. Próbáltam az ügyet otthonról kézben tartani, de 10 megkeresésből általában 1 választ kaptam, az sem tartalmazta világosan a kérdéseimre elvárt információkat. Csak itt derült ki amikor telefonon hívogattam az irodákat, hogy egy-két hónapra sem kiadó lakás, sem kiadó szoba nincs, legalábbis közvetítők ilyennel nem foglalkoznak. Tehát változott a terv: családi lakást kell keresni. Itt az a szokás, hogy az ingatlanos ingyen bemutat lakásokat és csak akkor kell fizetni, ha ki is veszem valamelyiket. Akkor viszont nem keveset, általában egy havi lakbér a járandóság. Ezért a pénzért viszont körbevisznek a városon, ami nagyon jó alkalom arra, hogy egy kicsit képet kapjak arról, hogy milyen környékek vannak, hol milyen emberek élnek, milyen a forgalom. Az sem utolsó dolog, hogy a közvetítők alaptermészetüket tekintve ritkán zárkózott, nehezen kommunikáló emberek, így elég sok mindent megtudtam sokféle váratlan témáról. Például az egyikük unokaöccse holland válogatott focista (az EB-n nem szerpelt, mint utólag kiderült), aki kamaszkorától a Chelseaben játszik, most épp a Hambrugban van kölcsön, egy másik hosszan ecsetelte a királynő szerepét (ami annyira látszólagos, hogy a nemzeti ünnepként jegyzett tradícionális elemekkel bőven meghintett éves parlamenti megnyitóját is (ami kötelezően szerepel minden holland utikönyvben) a mindenkori miniszterelnök írja (irattatja) meg. Szerencsére a harmadik napon találtam egy jó lakást, a negyedik napon pedig egy még jobbat. A közelben két "park" (pontosabban erdő) van, az egyikben (Hagse Bos - "a hágai erdő") van a királyi palota (tőlünk néhány száz méterre, de a fáktól nem látni), a másik pedig a Clingendael park, ami számos hágai nevezetességnek ad otthont (lásd: http://nl.wikipedia.org/wiki/Landgoed_Clingendael), például a csodálatos japánkertnek, ami minden évben csak hat héten át tart nyitva. A lakást a japánkert pagodájában ülve foglaltam le. Két hónapig az üres lakásban laktam, végül a múlt hét végén érkeztek meg a holmijaink otthonról. Az első hetet egyébként a legolcsóbb hágai szálláson, egy youth hostelben töltöttem egy 8 fős szobában. Nem voltam katona, de most már van sejtésem, hogy milyen lehet, amikor az egész körlet egyszerre horkol. A lakáskeresés miatt az első héten reggeltől estig a városban lófráltam, és volt alkalmam néhány furcsa helyet felfedezni. A legmeghökkentőbb egy "Szomáliai árúk boltja" nevű üzlet volt, amit a villamosból láttam. Bár mindig is érdekelt Afrika, és XC-s munkatársamtól és barátomtól, a libériai-amerikai Mlen-Too Wesleytől, aki az utóbbi években visszament Nyugat-Afrikába sokat is hallottam a mindennapi életről, politikáról, vallásról, stb., de életemben meg nem fordult a fejemben, hogy elgondolkozzak azon, hogy milyen árúkat termelhetnek Szomáliában. Egy másik furcsaság, hogy az egyik villamospálya melletti park (egy 3-szor 30 méteres, keritéssel elválasztott sáv) a város közepén szabályosan be volt veteményezve. Sajnos nem láttam ki műveli, és sikerült-e a produkció.
A MUNKÁRÓL. Az Europeana egyrészt egy portál, másrészt különféle európai digitalizációs projekteket összefoglaló ernyőszervezet. Leegyszerűsítve: ha az Unió pénzt ad digitalizálásra, akkor elvárja, hogy a végtermék (természetesen nem kizárólagos módon) jelenjen meg a portálon. Az adatszolgáltatók (ebből több mint 2200 van) a digitális anyagaikról szóló információkat (metaadatokat, pl. név, cím, bélyegkép, linkek stb.) begyűjthetővé teszik, a portál pedig egy helyen teszi kereshetővé az összes gyűjtemény anyagát. Jelenleg 23 milló objektumunk (a többesszámot értsd: nekünk, európaiaknak) van, ami 3 év múlva 30 millióra fog növekedni. Fontos, hogy a portál ezeket az anyagokat nem tartalmazza. A felhasználó végül az adatszolgáltatók oldalain köt ki, és ott nézheti meg a digitális állományokat. A portál 2008-ban indult, idén októberben fog megújúlni (a testvér projektünk, az Európai Könyvtár új portálját (http://theeuropeanlibrary.eu) éppen tegnapelőtt - 2012. június 25-én - nyitották meg Tartuban). A megújulás elsősorban tartalmi lesz: az eddigi ESE nevű metaadat-szabványt, ami a Dublin Core némileg felhabosított változata volt, ez EDM váltja, ami egy sokkal flexibilisebb, és a szemantikus web felől tervezett adatmodel. Továbbá: kitűzött cél, hogy a portál API-ja a portál minden alapvető szolgáltatását (facetták, breadcrumb, összetett keresés, natív adatstruktóra, felhasználói beállítások) közvetíteni fogja. A fejlesztési csoport - mint ahogy az egész Europeana -, nemzetközi csapat: finn, norvég, svéd, görög, skót, holland és amerikai emberek a közvetlen munkatársaim. A helyszín a Koninklijke Bibliotheek (Királyi Könyvtár), a hágai központi pályaudvar közvetlen közelében. (Mellesleg: a központi pályaudvar egy úgynevezett "fejpályaudvar", vagyis nincs áthaladó forgalom, olyan, mint a Nyugati Budapesten, de ez ha lehet még közelebb van a belváros szívéhez. Nagyon idegesített, amikor otthon pont az ilyen típusú állomások megszüntetése mellett érveltek, mondván, hogy a csodálatos Eiffel-csarnokot lehetne kávézónak, vagy múzeumnak használni. Itt Hágában ez a pályaudvar úgy van kialakítva, hogy az alsó szinten vannak a vágányok, a felső szint egyik részén pedig villamosmegállók, másik részén autóbuszpályaudvar és az elmaradhatatlan 3 szintes bicikliparkoló kapott helyet. Bár most éppen még felújítás és átépítés is van, valamiképpen sikerült megoldani, hogy minden közlekedési eszköz és gyalagos akadály nélkül utat találjon. Ehhez persze mindenféle építészeti "zsebcselekre" volt szükség (így nevezte Hrabal Hidegkúti zsebkendőnyi területen végrehajtott mozdulatait), például néhány villamos keresztülhalad a könyvtár épületén (lásd például itt: http://www.sportgeschiedenis.nl/2009/05/14/nalatenschap-henk-de-groot-naar-kb.aspx)).
HAZA, CSALÁD. Az isteni dolgokkal nem foglalkozok, mert vallási szempontból (egyáltalán transzcendentálisan), miként Max Weber fogalmazott tökéletesen süket vagyok. A család hiánya nehéz ügy, főleg a kezdeti, internet-mentes időszakban. Utánna már volt Skype és tudtunk beszélgetni, mesét olvasni, néha még játszani is. Nem voltam otthon az egyik lányom szülinapján, de vettem neki ajándékot, egy Elmo figurát, akiről esténként kiderült, hogy nagyon vicces mutatványokra képes, például tud kopogni a szemével. Egyszer voltam is otthon egy hétvégére, akkor Elmót hazavittem és kaptam helyette egy bohócot, hogy ne legyek egyedül. Nem volt jó tudni, hogy a párom bírkózik meg otthon a dolgokkal (nem csak a gyerekekkel, de az egész otthoni életünket bizonyos módon fel kellett göngyölíteni) és én nem tudok neki segíteni. Tudtuk, hogy ez így lesz, fel is készültünk rá amennyire lehet. Így a végéhez közeledve mmindketten úgy gondoljuk, hogy nagyobb bonyodalmak nélkül megúsztuk. Sokan mondják, hogy az első három hónap elég kemény. Én az első három hetet éreztem annak, de ez is megmaradt egy bizonyos szinten belül. Alapvetően nagyon sok jó, és viszonylag kevés váratlan rossz dolog ért. A legnehezebb mindenképpen az ő hiányuk volt. A haza, nos ezzel meg nagyjából úgy vagyok mint Kemény István mostanában sokat idézett versének (Búcsúlevél) alanya, vagy az a régi Cseh Tamás sor ("nem hí a haza"). Alapvetően patrióta vagyok, névtelenül, önkéntesen elég sok mindent tettem és teszek azért, hogy a kultúránk széles spektruma elérhető legyen, de mivel a kritikus és forrásközeli történeti iskolán nőttem fel (Mályusz, Kosáry, Fügedi, Engel, Kulcsár, Bessenyei stb.), mely élesen elkülönítette azt ami a valóban, igazolhatóan megtörtént attól, hogy a szívünkben mit érzünk, ezért sose ragadott el a hevület egy nacionalista irányba.* Kundera írta (ha jól emlékszek A regény művészetében), hogy ahol a hatalom lírai nyelvet használ, valaminek az elfedésében mesterkedik (ő persze még a népi demokratikusországokra utalt, de sajnos igaz máshol is -- a könyv nincs itt nálam, pedig jó lenne pontosan idézni, mert nem biztos, hogy vissza tudom adni a gondolatot). A jelenlegi otthoni közállapotokat olyan sokan leírták, hogy felesleges lenne ismételni, ráadásul az élet bonyolult, és néhány mondatban nem is sikerülne kifejteni a véleményemet. A lényeg: én nem hagytam el a hazámat, de most éppen máshol élek. Amit tudok innen teszek annak érdekében, hogy az otthoni közgyűjtemények fennmaradjanak, és korszerű módon betöltsék a szerepüket. Szerencsére a munkahelyem erre egyúttal apropó is, és az eddigi idő alatt is volt lehetőségem információkat közvetíteni.
(folyt. köv.)
* Akit érdekel a magyar történelemről való gondolkodás, de nem akar/tud száraz(nak tűnő) szaktudományos munkákat olvasni, továbbá úgy gondolja, hogy pl. Trianon kérdésére nem a harangozás az adekvát válasz, de egyúttal azt sem hiszi, hogy a Brit Birodalom elmúlása jó hasonlat lenne a történtekre, azoknak ajánlom Bodor Ádám A börtön szaga című interjúkötetét (a linkre kattintva el lehet olvasni a teljes könyvet). Bodor amellett, hogy ragyogó író (Vissza a fülesbagolyhoz, Sinistra körzet, Az érsek látogatása, és így tovább), kamasz korában a maroknyi aktív fegyveres (!!!) ellenáló táborát erősítette az 50-es évek legelején Kolozsvárott, amiért néhány év Szamosújvári börtön, majd 30 év mindenféle perifériára szorítottság (a magyar kisebbség perifériája, a református egyház perifériája, az írói közösség perifériája stb.) volt az osztályrésze. Időközben volt alkalma gondolkodni és olvasni. Amit ennek alapján elmond Trianon előzményeiről és máig ható következményeiről, annál én nem olvastam még tárgyilagosabb és (szerintem) pontosabb képet.
(Megjegyzés: a bejegyzést június végén írtam, pár napra rá megérkezett a családom.)
7 komment
in_array() vs isset()
2012.02.28. 13:09 kirunews
Sometime I need to test whether a given value is in a list. In PHP there is a built in function in_array() which does this test. But under the hood it might make use of an iteration, comparision of each list element, and the original value. This iteration might take some time. There is another method which takes two steps. The first step is to convert the original list (array) into an associative array, where the keys will be the elements of the list, and their values will be 1. Then in the second step we simply check the existence of the key with the familiar isset().
// the list
$list_of_values = array('one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten');
// some values to test whether they are in the list
$values_to_test = array('one', 'blue', 'green', 'two', 'fourty', 'six');
$testables_count = count($values_to_test);
$test_count = 100000;
// first method: in_array()
$t0 = microtime(TRUE);
$found = $not_found = 0;
for($i=0; $i < $test_count; $i++) {
$test_value = $values_to_test[$i % $testables_count];
if (in_array($test_value, $list_of_values)) {
$found++;
}
else {
$not_found++;
}
}
$t1 = microtime(TRUE);
printf("Found %d, not found %d in %.3f\n", $found, $not_found, ($t1-$t0));
// second method
// step one: creating an associative array
$tassoc0 = microtime(TRUE);
$list_of_values_as_assoc = array_flip($list_of_values);
$tassoc1 = microtime(TRUE);
// step two: testing the values
$t0 = microtime(TRUE);
$found = $not_found = 0;
for($i=0; $i < $test_count; $i++) {
$test_value = $values_to_test[$i % $testables_count];
if (isset($list_of_values_as_assoc[$test_value])) {
$found++;
}
else {
$not_found++;
}
}
$t1 = microtime(TRUE);
printf("Found %d, not found %d in %.6f + %.3f\n", $found, $not_found, ($tassoc1-$tassoc0), ($t1-$t0));
The result is that our original preconception was true, the in_array simply iterates over the list, so it is 10-20 times slower, than the second algorithm. Moreover, the in_array method speed is depending on the order or items in the list, while the second approach is pretty constant. So if the code has a lots of such tests, it is worth to transform the list to an associative array.
Update: I would like to say a thank to Szabó Dénes (@szabodenes) that he called my attention to the array_flip() method, which makes it easy to create an associative array from a simple list-type array.
Szólj hozzá!
Címkék: drupal
KIT-kérdés az elbocsájtásról
2011.11.25. 10:19 kirunews
A KIT november 21-i számában Mikulás Gábor értékelte egy korábbi szavazás eredményét, amiben a válaszadók az "Ön szerint ELSŐSORBAN milyen alapon várható 20%-os elbocsátás?" kérdésre adhattak választ. MG nagyon sokszor betalál a kérdéseivel egy-egy fontos problémába, és felvet fontos kérdéseket, de valahogy az az érzésem, hogy nem ritkán fordul elő, hogy a témaérzékenysége és bátorsága nem jár együtt módszertani precizitással, forráskritikával és néha megfelelő tájékozottsággal. Ugyanakkor mivel a Katalisten nagyon sokszor érdemtelenül, és személyében, nem pedig gondolataiban vagy cselekedeteiben bírálják, ami az erre érzékenyeket önkéntelenül a támadott oldalára állíthatja, továbbá mivel a Mikulás-kritika óhatatlanul egyfajta állásfoglalásnak is tűnhet a "porosodó", "könytár 2.0" stb. témákban, nagyon nehéz MG-vel kapcsolatban állításokat megfogalmazni. Most mégis ezt fogom megkisérelni.
MG kérdései:
- Az igazgató csókosai maradhatnak.
- A nyugdíjtól távolabbiakat tartják meg.
- A fiatal tehetségek maradnak.
- Az eddigi objektív teljesítmény számít (a jók maradnak)
Mi ezzel a bajom? Alapvetően az, hogy ez meglehetősen szubjektív, és nem tényekre, hanem véleményre épülő kérdés. A későbbi végeredményt, szinte mindenki kitalálhatja. MG elemzése is hagy kivánnivalót maga után, mert ő maga is keveri a vélekedéseket a tényekkel ("A szakmában a munka becsülete vagy a jövő szempontjainak képviselete e kérdésben sem játszik komoly szerepet."). Nem vagyok szociológus vagy pszichológus, akiknek az efféle kérdőívek készítésének a szakértői, de annyit tudok, hogy ennek van egy komoly módszertana, én nem hiszem, hogy fair dolog keverni az objektív, érzelemmentes, tényekre épülő, valamint a szubjektív, érzelmekre épülő, sőt azokat hangoló kérdéseket. (Két külön kérdésben ennek lehet relevanciája.) Továbbá, a minta nagysága jelentősen meghatározza a válaszok reprezentativitását, vagyis azt, hogy ez mennyire jellemző a teljes sokaságra. Ha a minta alacsony, akkor abból messzemenő számszerűsített következtetéseket nem érdemes levonni, mert a mérésnek nagy a hibahatára. MG többször is a válaszok közti négyszeres eltérésre hivatkozik, ami jelenhet tendenciát, de nem hiszem, hogy extrapolálni lehet, és így aztán teljesen felesleges kihangsúlyozni is.
Hanem ami fontosabb, az az alapkérdés, vagyis, hogy valóban milyen tendenciák érvényesülnek az elbocsájtásoknál, valamint - ami ehhez szorosan hozzátartozik - felvételeknél, vagyis hogyan gazdálkodik az intézmény a munkaerővel, igencsak releváns. A nehézség, hogy erre hogyan tudnánk felelni. A Gábor által feltett kérdés ugyanis ennek a munkaerőgazdálkodásnak a PR-ját méri, azt, hogy ebből mi látszik a többi munkatárs számára. Csakhogy a felvétel és elbocsájtás alapvetően nem nyilvános aktus (erről majd később, a mellékletben), a többiek csak azt látják, hogy van egy új arc, vagy hogy már nincs egy régi ('mióta is?'), illetve hallanak pletykákat. Azok, akiknek tényleges információjuk van, azok a döntéshozók, illetve az érintett munkatárs. Hogy lehet ezt mérni? Egyrészt feltételezhető, hogy a folymatoknak van dokumentációja, ha nem is a döntésnek, de a felvétel/elbocsájtás tényéről, illetve az érintett személyek alapadatai megvannak, ebből az életkorra vonatkozó kérdéseket el lehet dönteni, mert kiderülhet, hogy van-e bármilyen tendencia akár egy-egy korcsoport privilegizálására, akár a szempont figyelmen kívül hagyására. A "tehetség" és az "objektív teljesítmény" már egy ennél fontosabb mérőszám meglétét feltételezi, a munkatársak folyamatos évenkénti értékelését. Régen dolgoztam magyar munkahelyen, annak idején én sehol nem találkoztam értékeléssel, és nem tudom, hogy létezik-e. Néhány éve külső konzulánsa vagyok a Rochesteri Egyetemi könyvtárnak. Az egyetem minden munkatársa részt vesz egy évenkénti értékelésben. Ez rém nézve nem lenne kötelező, de úgy döntöttünk, hogy én is részt veszek ebben a programban. Az értékelésnek legalább három része van. Egymástól függetlenül létrejön két írásos értékelés: mind a közvetlen főnök értékeli a bosztottjait, mind a beosztottak saját magukat. Az értékelésnek vannak kötött, kérdőív jellegű pontjai, mind kifejtendő részei. A következőkre terjed ki a feladat: milyen fontosabb dolgok történtek az elmúlt évben? mik a jövőre kitűzött célok? milyen eszközök, lépések segítik a munkát, amik jelenleg hiányoznak? hol látjuk a javítás lehetőségeit? mik a személyes tervek (amik nem köthetőek közvetlenül a munkához, de a képességek fejlődése kihattásal lehet erre is, pl. nyelvtanulás, sport)? A főnök ezen felül előírt szempontrendszerben is pontoz és értékel, pl. külső-belső kommunikáció, rugalmasság, (szakmai) megbízhatóság stb. Az írásos értékelést egy kb. egy órás szóbeli megbeszélés is követ, ahol a felvetett kérdéseket meg lehet beszélni, meg lehet kérdezni, hogy miért kapott az ember ilyen-olyan besorolást, tanácsot kérhet és adhat stb. A folyamat során keletkezett dokumentumok nagy hatással vannak a munkahelyi előrementelre, jutalmazásnál, fizetésemelésnél is ezt veszik elsősorban figyelembe. Új vezető belépésekor is nagyon hasznos, mert képet kap a munkatársakról. Ha megvan ennek az értékelésnek az archívuma, akkor összevetve a munkaerőgazdálkodás adminisztratív anyagaival viszonylag egyszerűen eldönthető, hogy a felvett munkatárs beváltotta-e a tehetségéhez, képességeihez fűzött ígéreteket, illetve az elbocsájtások során valóban azok távoztak, akik az értékelések alapján a legkevésbé mozdították előre az intézményt.
Ha nem áll rendelkezésre ilyen dokumentáció, akkor ki lehet indulni külső tényezőkből: előadások, cikkek, publikált szoftverek, vagy látogatószám, felhasználói elégedettség stb. de ezek egytől-egyig meglehetős szubjektivitással értékelhető tényezők, ráadásul nem minden szakterületnek vannak ilyen mérőszámai. Mindenesetre a pletyka-alapú benyomásnál azért erősebb szempontrendszert lehet ezekből kialakítani.
Végezetül lehet az érintettekkel interjúkat készíteni, ebben az esetben az fogja befolyásolni az értékét, hogy a vezetőknek a saját cselekedeteiket kell minősíteni (mivel erre más nem lesz képes információhiányban).
Ha a vezetők érintettek a sikerességben, és ennek a sikerességnek vannak valamilyen matematizálható, mérhető összetevői (tudva és elfogadva persze, hogy egy sor dolgot nem lehet mérni), akkor a munkatársi értékelés fontos támpontokat adhat mind a felvétel, mind az elbocsájtás tervezésekor, és segíti a könyvtárat, hogy a lehető legkevesebb véráldozatot hozza, és a feladatok szempontjából leghasznosabb munkatársakkal tudja átvészelni a nehéz időket. Ha a rochesteri értékelés mechanizmusának részletei felkeltették valaki érdeklődését, akkor szívesen megadom annak elérhetőségét, aki nálam bővebb információkkal tud szolgálni. Felteszem máshol is van hasonló rendszer.
Melléklet: igazgatókeresés a rochesteri egyetemi könyvtárban
Korábban írtam, hogy a felvétel és elbocsájtás alapvetően nem nyilvános aktus, viszont a felsővezetők kiválasztása kivétel lehet. Rochesterben éppen most folyik egy igazgatóváltási procedúra. A korábbi igazgató Susan Gibbons júliustól a Yale könyvtárának igazgatója lett (a Yale Daily Newsban a "könyvtáros szakma Michael Jordanjának" nevezte az igazgatóválasztási bizottság elnöke), azóta megbízott igazgató irányítja a könyvtárat, amivel párhuzamosan elindult a leendő vezető keresése. A kiválasztásra létrehoztak egy egyetemi ad hoc bizottságot, amiben a különböző szervezeti egységek képviselik magukat. A bizottság felállított egy nyilvános kritériumrendszert, ami összhangban van a könyvtár stratégiájával, például nagy hangsúlyt kap a könyvtár-informatikai innováció. A jelentkezők lehetőséget kapnak arra, hogy személyesen konzultáljanak a könyvtár dolgozóival, és bizonyos meghallgatások is nyilvánosak. A bizottság nem csak várja a jelentkezőket, hanem profi fejvadászcéggel is keresteti az alkalmas vezetőt. A folyamat állásáról a bizottság és az ügyvezetők időről-időre beszámolnak. A tagok neve, elérhetősége szintén nyilvános, bármilyen felmerülő szempont figyelembevételét lehet javasolni. A processzus lényegében megegyezik a középvezetők esetében is, az egyetlen különbség az erőfeszítés mértéke: kevesebb fordulóban, kevesebb szinten döntenek.
1 komment
SSH csatornák
2011.11.08. 12:42 kirunews
Régi problémám, hogy nehézséget okoz az adatoktól függő hibakeresés ha az adatokat nem tudom teljes körűen reprodukálni a saját gépemen. Például egy Solr index elkészítéséhez - most nem ismertetetndő okok miatt - kellhet akár egy egész munkanap, a kész, távoli szerveren lévő index letöltéséhez pedig még több is (sajnos az internetszolgáltató által kínált kapcsolat sebessége éppen, hogy átlépi a minimális értéket). Egy ideje sejtettem, hogy az SSH csatorna nevű technológia segítségével megoldható a probléma, és a távoli erőforrást helyi erőforrásként lehetne láttatni, de amikor próbálkoztam ezzel, mindig vakvágányra futottam (az SSH egyszerűen túl sok mindent tud, és nehéz kibányászni célirányosan azt, amire éppen szükség van). Viszont néhány napja megvettem Christopher Negus és Francois Caen Ubuntu Linux Toolbox című könyvét (Wiley, 2008), amiben világosan le van írva a probléma és a megoldása, ami nevetségesen egyszerű:
ssh -L <helyi port>:<helyi gép>:<távoli port> <távoli felhasználó>@<távoli gép>
például
ssh -L 8983:localhost:8983 developer@example.com
Ez azt csinálja, hogy a távoli gépen pl. 8983 porton keresztül elérhető szolgáltatást elérhetővé teszi a helyi gép adott portján (pl. localhost:8983). Mivel a Drupal XC moduljait fejlesztem, a megrendelő könyvtár bibliográfiai adatbázisát ezen a módon a saját gépemről is elérem és tudom a megjelenítés vagy a működés kisebb-nagyobb hibáit reprodukálni, nyomon követni, elemezni és végül javítani. Chx felhívta a figyelmemet (köszönet!), hogy a mezei ssh helyett lehet az autossh-t is használni, ami anyival tud többet, hogy a kapcsolat megszakadása esetén (ami inaktivitás következtében elő-elő fordul) mindenféle kézi beavatkozás nélkül automatikusan újra csatlakozik a távoli géphez. A parancsot ugyanígy kell indítani, csak ssh helyett az autossh parancsot kell használni (ami nem része az alap Ubuntu kiszerelésnek, így külön kell telepíteni).
Ilyen módon mindenféle, adott porton keresztül elérhető szolgáltatást (leginkább valamilyen adatforrást, pl. adatbázist, indexet) be lehet csatornázni a saját gépünkre. Nagyon fontos viszont, hogy gondoskodjunk arról, hogy az adatokat nem módosíthassuk, pusztán olvasási módban nyissuk meg őket, amihez az adott szolgáltatás jogosultságai kel úgy beállítani, hogy csak adott műveleteket engedjen meg a bejelentkezett felhasználónak.
Szólj hozzá!
Nagyapám, Kiss Imre
2011.10.17. 09:47 kirunews
Iparos és földműves volt. Mindkettő egyszerre, amennyire tudom egész életében. A családján kívül ez a két dolog érdekelte igazán, a kert és a vas. A legjobb persze az volt, ha ez a kettő együtt járt. Ezen töprengett, spekulált, ehhez gyűjtötte az anyagot, ha kellett ezt rajzolgatta. Készített egyszerűbb és bonyolultabb szerszámokat a fejszétől a traktorig, kerítéstől, ólajtótól a hozzá való, emberes méretű és súlyú lakatig. Legtöbbször saját használatra, de volt, hogy kijárt a piacra is velük. Korábban lovakat patkolt, kocsikerékre szerelt abroncsot, aztán hatalmas gőzmozdonyokat javított.
Sok vashoz sok erő kell, de a testi erőnél is több akaraterő szorult belé. Kevés parancs lehetett számára erősebb, mint, ha felkelt a nap, dolgozni kell. Hidegben, melegben, egészségesen és betegen is. Volt, hogy hónapokig nem tudta rendesen használni a kezét egy betegség miatt, akkor Mamával olyan kesztyűt és egyéb készségeket csináltatott, amivel valahogy odakötözte a kapát a kezéhez és úgy dolgozott. Mert olyan nem lehetett, hogy ne legyen kész a kert.
Kemény ember volt, kevés szavú, a végtelenségig készséges és önfeláldozó. Egyetlen pillantra sem emlékszek, amikor a saját hasznát, netán a kényelmét másoké elébe helyezte volna. Különféle szenvedélyek nem érintették meg, vagy nem érdekelték, sőt talán (a szurkolást és a rejtvényfejtést kivéve) kikapcsolódni sem szeretett, ellenkezőleg, éppen a bekapcsolódás, a munkálkodás az, ami hajtotta.
Szeretett beszélgetni a vele egyívásúakkal, akik - akárcsak ő - földművesek és iparosok voltak. Szerette a technikát, a gépeket és szerette megoldani az elromlott gépek támasztotta rejtvényeket. Szeretett biciklizni, motorozni, és autót vezetni, de le tudott ezekről mondani amikor ennek eljött az ideje. Szeretett olvasni, főleg a barkácsolással és a kerttel kapcslatos könyveket, de szerette a történelmet, és a térképeket is. Izgatta a politika és a sport, mindkettővel kapcsolatban átélt nagy lelkesedéseket és nagy csalódásokat. Sok mindent tudott, sok mindenben tájékozott volt. Büszke volt a családi ősökre, akik között voltak magyarok, svábok, híresek, és névtelenek, egy vitéz kapitány és sok-sok kétkezi munkás. Édesapja az első világháborúban, az isonzói csatatéren érzékelhette meg a történelem árnyoldalát, neki magának az évszázados gyökerű tanyasi életmódtól való megfosztatással kellett megbírkóznia. Nagy ajándék, hogy élete végére újra olyan hajlékba tudtak költözni, melyet kert vett körül, mint egykor.
A paraszti erényeket és elveket mindvégig megtartotta. Nem szemetelt és nem volt feleslegesen terhére környezetének, beosztással élt, nem pazarolt, nem hagyta veszendőbe menni a dolgokat. Megbecsülte a tárgyakat és különösen megbecsülte az ételt. Nem szerette a kivagyiságot, a felszínességet, a rikítót. Nem szerette ugyanakkor a dolgok elmismásolását sem. Bár rendkívüli ereje és szívóssága lehetővé tette volna, hogy részt vegyen különféle konfliktusokban, ő - talán felmérve, hogy milyen károkat tudna okozni, - Arany János módjára inkább békésen félreállt, és folytatta a munkáját.
Hagyott hátra néhány viccet, a tekintetét, amivel a dédunokákat csodálta, egy-két metszőollót, tán még pálinkát is. Egy papírt, hogy “tengeri van eladó”, könyveket, vasakat, megjavított keritést, homokozót a kicsiknek.
Élt egyszer egy ember. Nyolc betű.
Szia, Papa!
(2011. október 14-én, a debreceni Köztemetőben, nagyapám sírjánál mondtam el ezt a búcsúbeszédet.)
Szólj hozzá!
A spanyol közös katalógus és az XC
2011.09.13. 10:16 kirunews
Néhány hete érkezett egy váratlan levél, amiben Domingo Arroyo Fernández arról értesítette az eXtensible Catalog közösséget, hogy még az év elején a spanyul kulturális minisztérium elhatározta, hogy az összes állami ellenőrzés alatt levő spanyol könyvtár (közel ezer könyvtárról van szó) közös katalógusát XC alapon készítteti el. Készült is erről egy közel 60 oldalas tanulmány http://hdl.handle.net/10421/
Szólj hozzá!
SPARQL röviden
2011.07.05. 22:44 kirunews
Az alábbi leírás a Jena nevű Java könyvtár SPARQL tutoriáljának, illetve a SPARQL szabványnak a rövidítése és némileg átdolgozása.
A SPARQL az RF-hez készült lekérdezőnyelv. Olyan, mint az SQL, vagy a kevésbé ismert XQuery, Z39.50 stb. Az a célja, hogy lehetővé tegye az RDF-ben tárolt tripletekből (állításhármasokból) álló adathalmazt. Mint annyi mást, ezt is a W3C szabványosította, elérhető innen: http://www.w3.org/TR/rdf-sparql-query/.
A SPARQL mint nyelv eléggé elterjedt ahhoz képest, hogy nincs hozzá túl sok megvalósítás. Ha az alábbi példákat, vagy ehhez hasonlóakat ki akarunk próbálni, legegyszerűbb, ha a CKAN archívumban keresünk olyan adatforrást, aminek van SPARQL végpontja. Aki saját SPARQL szervert akar építeni, annak a nyílt forráskódú Joseki szervert ajánlom (Java futtatókörnyezetet igényel), elérhető innen: http://joseki.org/. Ebben található néhány egyszerű (tényleg nagyon egyszerű) minta adatbázis, de könnyen lehet importálni (például a CKAN-ról letöltött) N3, Trutle (ttl) vagy RDF formátumú adathalmazokat.
1. Egyszerű SELECT
SELECT ?x
WHERE {
?x <http://www.w3.org/2001/vcard-rdf/3.0#FN> "John Smith"
}
Ahogy az RDF is alany-állítmány-tárgy (subject-predicate-object) hármasból ál össze, úgy a lekérdezés is. Az ?x egy változó. A SELECT utáni jelentése az, hogy ezt a változót szeretném visszakapni a kérdés futtatása után. A WHERE-en belül pedig az állítás alanyát jelenti. A kérdés magyarra fordítva tehát úgy hangzik, hogy keresem az alanyát azoknak az állításoknak, melyek valakiről azt mondják, hogy a családneve "Smith", egyszerűbben: keresem a Smith nevűeket.
2. Több mező SELECT-je
SELECT ?x ?fname
WHERE {
?x <http://www.w3.org/2001/vcard-rdf/3.0#FN> ?fname
}
Itt a visszaadott elemhez hozzáadtuk a nevet is, és nem szűkítettük a kört a Smithekre, hanem mindenkit lekérdezünk, akinek van családneve.
3. Több feltétel
SELECT ?givenName
WHERE {
?x <http://www.w3.org/2001/vcard-rdf/3.0#Family> "Smith" .
?x <http://www.w3.org/2001/vcard-rdf/3.0#Given> ?givenName
}
Keressük a Smithek keresztnevét.
4. Prefixek használata minősített nevek (QName) helyett
Ha a kérés elején deklarálunk egy névtér prefixet, akkor nem kell kiírnunk a teljes névteret a kérdés belsejében.
PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0#>
SELECT ?givenName
WHERE {
?x vcard:Family "Smith" .
?x vcard:Given ?givenName
}
5. Mintaillesztés
FILTER regex( ?x, "minta" [, "módosítók"])
A minta és módosítók az XQueryben definiált módon működnek, ami egyébként követi a Perlben megszokott szerkezetet.
SELECT ?g
WHERE {
?x vcard:Given ?g .
FILTER regex(?g "r", "i")
}
Megkeresi azokat a keresztneveket, amelyek nagy vagy kis r betűt tartalmaznak (i = ignore case).
6. Értékalapú szűrés (csak semmi áthallás)
SELECT ?resourceA 24 évesek és idősebbek leválogatása.
WHERE {
?resource info:age ?age .
FILTER (?age >= 24)
}
7. OPTIONAL - opcionális szűrés
Néha akkor kell szűrni, ha van mit. Ha nincs (mert adott mező nem található az adott állításban), akkor azokat az állításokat engedjük át. Többek között ezért is nevezik az RDF-et félig-struktúrált adatoknak, mivel megengedi bizonyos adatok hiányát (relációs adatbázisban mégha NULL értékkel is, de mindig ott van az adat).
SELECT ?name ?age
WHERE {
?person vcard:FN ?name .
OPTIONAL {?person info:age ?age}
}
Ha van age tulajdonság, megjelenítjük. Ha nincs, üres értéke lesz az eredménylistában (ahelyett, hogy ezeket a rekordokat egyszerűen kihagynánk).
8. OPTIONAL kombinálása FILTER-rel
SELECT ?name ?age
WHERE {
?person vcard:FN ?name .
OPTIONAL {?person info:age ?age .
FILTER (?age > 24) }
}
Ha van életkor tulajdonság, akkor csak a 24 évnél idősebbeket jelenítjük meg, illetve azokat, akik esetében nem ismert ezen tulajdonság értéke.
9. Metszet (UNION)
Az RDF természetéből következik, hogy ugyanazt a tulajdonságot több névtés is definiálja. Bár törekedni kell az egységesítésre, egy aggregált adathalmaznál erre nem mindig van mód. Ekkor jól jöhet az UNION.
SELECT ?name
WHERE {
{ [] foaf:Name ?name } UNION { [] vcard:FN ?name }
}
Ugyanezt FILTER alkalmazásával is el lehet érni:
SELECT ?name
WHERE {
[] ?p ?name
FILTER (?p = foaf:Name || ?p = vcard:FN)
}
Persze vannak esetek, hogy meg akarjuk őrizni azt, hogy mi is volt a tulajdonság neve a forrásban:
SELECT ?name1 ?name2
WHERE {
{ [] foaf:Name ?name1 } UNION { [] vcard:FN ?name2 }
}
Végül ugyanez OPTIONAL-lal:
SELECT ?name1 ?name2
WHERE {
?x a foaf:Person
OPTIONAL { ?x foaf:name ?name1 }
OPTIONAL { ?x vcard:FN ?name2 }
}
10.
Szólj hozzá!
MEK referensz-link feloldó
2010.12.16. 12:44 kirunews
Hosszú-hosszú vajúdás után most került végre pont egy régi ügyre.
Káldos János, aki ma már az Országos Széchényi Könyvtár különgyűjteményeinek (Kézirattár, Térképtár, Régi Könyvek Tára stb.) igazgatója, kb. 7-8 évvel ezelőtt, de lehet, hogy van az már tíz is, felvázolt egy fájlelnevezési nómenklatúrát, az úgynevezett Káldos-féle nevezéktant, ami meghatározta, hogy a régi könyves anyag digitális másolatainak milyen könyvtárstruktúrát és fájlneveket kell adni. A lényege ennek a nevezéktannak az volt, hogy a fájlnevek követik a magyar könyvtári rendszer logikáját, vagyis nem mesterséges sorszámokkal dolgozik, hanem a könyvek valós könyvtári jelzeteit veszik alapul. Ez azért jó, mert egy fájlra ránézve rögtön látszik, hogy annak mit kell tartalmaznia, ráadásul tudományos publikációkban egyszerűen lehet hivatkozni magukra az állományokra. János sajnos - mint a legtöbb könyvtáros - a kelleténél szerényebb ember és tudomásom szerint sohasem publikálta a vázlatát
Az OSzK-ban annak idején el is indult egy digitalizálási munka, de egészen pontosan nem tudom miért, ez a munka nem lett nyilvános. (Egy kis kitérő. Ha jól sejtem itt is közrejátszik az a félelem, hogy ha nyilvános és ingyenes a dokumentum, akkor a könyvtár elesik bizonyos bevételektől, aminek a beszedését a fenntartó - véleményem szerint káros módon - előírja. Káros, mivel a könyvtár (múzeum, levéltár stb.) nem az által hajt hasznot, hogy a szolgáltatásaiért pénzt szed be (ezek a pénzek a fenntartási költség nevetséges hányadát képezik), hanem azáltal, hogy a tudást, műveltséget, vagy akár gyakorlati információkat terjeszti. Minél kevesebb gát és akadály van az információforrások és a felhasználók között, annál hatékonyabb az információáramlás, és így a közművelődési intézmények tevékenysége. Ha korlátozzuk a hozzáférést, akkor a könyvtár hatékonyságát, az információterjedést korlátozzuk.)
Egy ideje részt veszek az egyik legrégibb magyar bölcsészinformatikai projekt, az RPHA munkálataiban. Az RPHA a XVI. századi magyar versek repertóriuma, és Horváth Iván indította el még a 70-es években. Az RPHA sokat módosult az idők során, volt "nagygépes", DOS-os ISIS-es, és mindenféle változata. Régi igény volt, hogy a benne szereplő verseket össze kellene kötni ezek digitális facsimiléivel. Mivel az OSzK-ban ezek nem voltak nyilvánosak, bekerült némi időbe, míg el tudtunk indítani egy kisérleti adást. A Huszár Gál-féle Énekeskönyv (RMNy 353) lett a kiválasztott mű, mivel ez közel 250 XVI. századi verset tartalmaz. A kötet felkerült a MEK-be (http://mek.oszk.hu/08800/08838/). Csakhogy a MEK-nek, mint látható már van egy kiszabott struktúrája, a kanonikus MEK URL-ek pedig nem felelnek meg a Káldos-féle nevezéktannak. Szerencsére az Apache webszerver (más webszerverek is) rendelkeznek egy URL átíró képességgel, ami lehetővé teszi, hogy logikai URL-eket rendeljünk hozzá a fizikai állományokhoz, vagyis egy fizikai állományt többfajta címzéssel is el tudjunk érni. Ehhez esetünkben a következő sorokat kellett beilleszteni az Apache egyik konfigurációs állományába:
<IfModule mod_rewrite.c>
RewriteEngine on
# Rewrite URLs of the form 'rmny/x' to the form
# 'reference_redirector.php?q=rmny/x'.
# It is case insensitive
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^((rmny|rmk)/.*)$ reference_redirector.php?q=$1 [NC,QSA]
</IfModule>
Ez az RMK/akármi URLeket átfordítja reference_redirector.php?q=akármi formába. A szrikpt feldolgozza a bejövő adatokat és ha van megfelelő oldal, vagy könyv egy HTTP fejlécben elhelyezett Location paranccsal átdobja a böngészőt a megfelelő helyre. Ha nincs ilyen, akkor a MEK címoldalára visz. A dolog lényege, hogy a linkek feloldását egy helyen kell karbantartani, a MEK oldalán és azt minden tudományos vagy ismeretterjesztő projekt használhatja. Nekik csak azt kell megjegyezniük, hogy hogyan is kell a linkeket megalkotniuk. Íme tehát egy rövid bevezető.
Hogyan alakítsunk ki referensz-linkeket a MEK állományokra?
A linkfeloldó jelenleg két sémát kezel, az RMNy és RMK referensz számokat, de még idén ez ki fog bővülni az ISBN számokra és az EPA (http://epa.oszk.hu) esetén az ISSN-ekre is.
RMK séma:
RMK/<az RMK kötetszám arab vagy római számmal>/<az RMK-szám>/<a referált kötet>(opcionális)/<oldalszám>
RMNy séma:
RMNY/<az RMNy-szám>/<a referált kötet>(opcionális)/<oldalszám>
ISBN séma:
IBN/<ISBN szám>
A séma neve nem kisbetű-nagybetű érzékeny, bármit lehet használni. Az oldalszámok esetén lehet A, B, R, V betűkkel jelezni a recto-verzo oldalpárokat. A számokat fel lehet tölteni 0-val (néhány adatbázisban ezt alkalmazzák), például 0003, de lehet feltöltés nélkül is alkalmazni.
Példák:
http://mek.oszk.hu/rmny/353 (nem adtunk meg oldalszámot, így a kötetre ugrik)
http://mek.oszk.hu/rmny/353/1/3
http://mek.oszk.hu/RMNy/0353/1/0003A
http://mek.oszk.hu/RMNY/0353/1/0003r
http://mek.oszk.hu/RMK/1/0332/1/0003A
http://mek.oszk.hu/rmk/I/0332/1/0003A
http://mek.oszk.hu/ISBN/9637593403
http://mek.oszk.hu/isbn/963034792X
Mint a bejegyzés elején említettem jelen pillanatban ez az egy kötet töltötte be a próbababa szerepét, de hamarosan elkészül a feloldás a MEK-ben tárolt többi RMK-jellegű kötetre is. Sajnos a legtöbb PDF formában van tárolva, és nincs oldalszám összevetésük, tehát ezek esetében a kötetre fog a böngésző ugrani és nem a pontos oldalra. Ám ha bárki késztetést érez magában, hogy oldalszámokat oldjon fel fizikai képfájlokra, vagy PDF oldalszámokra, kérem, hogy küldjön nekem egy egyszerű szövegállományt a következő formában:
<kötetszám>/<oldalszám>;<MEK-oldalszám>például:1/0005A;014Ebben az esetben a kötetszámot arab számmal, a recto-verzo jelölést pedig A, B betűkkel kell megadni.
1/0014B;024
Problémák
Meglehet, hogy vannak olyan esetek, amikor a korabeli nyomdák a lapszámozásokat tökéletesen végezték, a Huszár Gál-féle énekeskönyv esetében erről nincs szó. Találhatók benne újrakezdett sorszámok (van olyan oldalszám, ami háromszor is felbukkan), és felcserélt ívek (ezeket betudhatjuk a könyvkötőt megzavaró történelmi viharoknak is, ne szegény nyomdászt szídjuk érte), ezért nem lehet egyszerű képlettel előállítani a könyvoldal-fájlnév megfeleltetést. Arra, hogy a többször előforduló oldalakat hogy lehetne megkülönböztetni az URL-ben egyelőre nincs ötletem, ha valakinek van, azt örömmel veszem.
6 komment
tar súgó
2010.11.23. 10:17 kirunews
Én általában zippelni szoktam, de van olyan gép, ahol nincs zip, illetve van olyan becsomagolni való, ami nagyobb, mint a zip fájl megengedhető legnagyobb mérete (4 GB). Nomeg a Drupalos modulokat is tar-ba csomagolják, én meg mindig googlizok, amikor ki akarok csomagolni, vagy be akarok csomagolni valamit, úgyhogy jöjjön a tar súgója.
becsomagolás
tar -cf file.tar file1 file2
ahol:
-c = create
-f = filename. Kötelezően ez az utolsó kapcsoló, különben hiba lesz
egyéb paraméterek:
-v = verbose
--remove-files <filename> = a létrehozás után törli az eredeti fájlokat
-help = súgó
-version = verzió infó megjelenítése
kicsomagolás
tar -xf file.tar
ahol
-x = extract
-f = filename (lásd mint fent)
Alapértelmezésben a tar csak csomagol, de nem tömörít. A tömörítő kapcsolók:
-j = bzip2
-z = gzip
-Z = compress
Ezeket lehet használni be és kicsomagolásnál. A zip-pel ellentétben a fájlnevet és a kiterjesztést is nekünk kell megadni.
tar -cjf myfile.tar.bz file1 file2 file3 // becsomagolás
tar -xjf myfile.tar.bz // kicsomagolás
Ha nem egy alkönyvtárba, hanem a munkakönyvtárba akarunk kicsomagolni, akkor a
--strip-components=1
kapcsoló az első alkönyvtárat nem fogja létrehozni.
tar --strip-components=1 -zxvf drupal-x.x.tar.gz
Törlés (csak tömörítetlen állományon működik)
tar -f file.tar --delete file1 file2
alönyvtár törlése:
tar -f file.tar --delete dir1/*
Szólj hozzá!
LITA National Forum 2010, Atlanta
2010.10.10. 17:33 kirunews
Jó szerencsémnek köszönhetően részt vehettem a 13. LITA National Forumon Atlantában. A LITA a Library and Information Technology Association rövidítése és az Amerikai Könyvtárosok Egyesületének az informatikai szekcióját jelöli. A konferenciára még januárban lehetett jelentkezni előadónak, majd egy elég hosszú értékelési fázis végén, április végén derült ki, hogy elfogadták az előadásjavaslatomat. A konferencia három és fél napos volt, ebből az első nap egy elő-konferencia, ahol egy-egy választható téma körül előadás és műhelymunka folyt. Én a könyvtári IT szolgáltatások virtualizációjáról szóló műhelyen vettem részt, ahol megalkottuk a Tim Berners Lee könyvtár infrastruktúráját (az épület szerkezetétől kezdve az alkalmazásokig). A konferencia szervezési elve az volt, hogy párhuzamosan hat előadás futott, de egy nap maximum öt előadást lehetett meghallgatni. Háromféle előadás volt: minden napra jutott egy nagy főelőadás ("keynote speech" - ha valaki tud jó fordítást, kérem jelezze, nekem most ez jött össze), ezen kívül 70 és 30 perces előadások voltak. Az előadások között hosszú szüneteket tartottak. Mindennek az eredmény, hogy a hallgatóság ideje nagy részében nem elsősorban az előadásokat hallgatta, hanem egymással beszélgetett, vitatkozott.
A konferencia vezető témái az (informatikai) felhő és a társadalmi hálózat voltak (The cloud and the crowd). Úgy tűnik, hogy a felhő már egészen kis könyvtárak esetében is nagyon fontos, és nemcsak, hogy megfontolandó hanem bizonyított eszköz. Az egyik előadáson egy idahoi könyvtári hálózat esettanulmányában egy 300 fős, isten háta mögötti Sziklás-hegységbeli település könyvtárát említette, amit olyan siker tudtak bekapcsolni az OCLC egyik új, még béta állapotú, "felhőre épült" hálózati szolgáltatásába, hogy a könyvtár szakkönyvtári minősítést kaphatott, és a település polgármestere az új szolgáltatások segítségével kaphatta meg a PhD fokozatát. (Én nem tudtam, de Idaho állam maga is olyannyira periférikus, hogy ez előadó az első dián egy USA térképen külön megjelölte, hogy merre is fekszik Idaho, illetve a vele gyakran összekevert Utah és Ohio).
A nyitó előadás a Wikipédiáról szólt, de erről a saját előadásomra készülvén lemaradtam. Többek számára a konferencia legjobb előadása volt, de sajnos nem maradt róla sem videó, sem írásos anyag. Remélem Amy Bruckman a későbbiekben fogja publikálni.
Tabatha Farney a weblapokra eső kattintások elemzésével foglalkozott - vagyis hova kattintanak a felhasználók egy adott oldalon. Az előadásában 3 kattintás elemző programot ismertetett (Google Analytics, ClickHeat, crazyeggs), de megemlítette, hogy ezen kívül még vizsgáltak egy sor másikat is, melyek nem fértek be a 30 percbe.Az elemzés konkrét eredményeket hozott, a könyvtár honlapját a néha meglepő, néha csak a könyvtári vezetés számára meglepő eredmények (alig voltak kíváncsiak a könyvtár saját működésével kapcsolatos főoldalra kitett linkekre) alapján áttervezték. Tabatha sajnos nem tért ki a találati oldalak klikk-elemzésére, ami engem jobban érdekelt volna, de nyitott a további párbeszédre, és mind az előadásából, mind a későbbi beszélgetések alapján látszott, hogy sokkal többet tud, mint amennyit az előadásába be tudott szuszakolni.
A napi utolsó blokkba került a saját előadásom is. Én eredetileg 30 perces előadással jelentkeztem volna, de az XC vezetői egyértelműen a 70 perces előadás mellett szavaztak, ami nagyon komoly szorongást váltott ki belőlem az utóbbi fél évben, hiszen ez volt az első eset, hogy főként anyanyelvi közönség előtt angolul beszélek, ráadásul több mint egy órát. Ennek ellenére szerencsére jól sikerült, ami főként a témának köszönhető (az eXtensible Catalog Drupal Toolkitjét mutattam be), amin tényleg sokat dolgoztunk.
A szombati kulcselőadást Roy Tennant tartotta a Felhő használatával kedveskedni a tömegnek (Using the Cloud to Please the Crowd) címmel. Roy egy tőle megszokott váratlat ötlettel kezdett. Miután néhány percet beszélt, csenget a telefonja. A főnöke hívta (pontotsabban ezt játszotta el). Az volt a kérés, hogy sürgősen össze kellene állítani egy Drupal szájtot, mert valami baj van a szerverrel. Az előadó ezután regisztrált az Amazon S3 szájton, keresett gyorsan egy Ubuntu szerver image fájlt, olyat, amiben van Drupal is, installálta a szervert, intallálta rajta a Drupalt, írt egy blogbejegyzést, és visszahívta a főnökét, hogy készen van. Az egész nem volt több mint öt perc, de lehet, hogy csak három (hozzáteszem, hogy Roy az OCLC kutatóintézetének "Senior Program Officer" alkalmazottja, ami azt jelenti, hogy tulajdonképpen nincs is efféle főnöke). Az előadás során volt még néhány meglepő lépése, például kiszámolta, hogy egy induló informatikai szolgáltatást néhány száz dolláros költséggel tökéletes szolgáltatói infrastruktúrával lehet ellátni (nyílt forráskódú irodai alkalmazások, az S3-hoz hasonló tárhelyek, ingyenes/olcsó csoportmunka és projektmenedzser alkalmazások, gerillamarketing (!) stb.).
Drupalos elfogultságom okán a délelőtt másik előadásának a Minesotai Egyetem Do it with Drupal-ját választottam. Az előadás arra fókuszált, hogy azokat megnyerje, akik korábban még nem használták a Drupalt. Arról számoltak be, hogy a könyvtári és egyetemi weboldalak különféle tartalmait hogy tették át Drupal alá, és ami korábban nem sikerült, hogyan tudták egy helyre összeszedni a különféle információkat (egyetemi naptár, terembeosztás, előadások, jelentkezések stb.)
Meglepő volt a JSTOR előadása, amiben bejelentették egy újabb bétaváltozat szolgáltatásait, illetve azt, hogy ez teljes mértékben elérhető API-kon keresztül. A következő honapokban - ha elérek odáig - mindenképpen fogok ezzel kisérletezgetni. Az volt a legfőbb meglepetés, hogy a teljes szövegű keresésben az előadó teljesen ugyanazon a vágányon haladt, mint amit korábban a Tesujiban én is szerettem volna megvalósítani (például az idézettségi indexek visszavezetése a relevancia súlyozására, tezaurusz/ontológia alapján történő keresés és mások), ráadásul azokat az eszközöket is használták, mint amit mi is használtunk (Lucene/Solr).
Szintén nagy meglepetés volt az egyik atlantai egyetem, az Emory könyvtárosainak előadása, akik a helytörténeti térképek és légifelvételek georeferált szolgáltatását ismertették. Kb. ugyanazzal a módszerrel dolgoznak, és ugyanazokat a célokat tűzték mi, mint az Arcanum.
Az aznapi utolsó előadás témája az OCLC emlegetett új béta szolgáltatása volt. Ez egy panel-előadás, ami azt jelentette, hogy ugyanazt a szolgáltatást 5 előadó, öt különféle szempontból ismertette. Az előadók egyike a készítő OCLC fejlesztője, a másik négy könyvtáros (kisebb-nagyobb egyetemek és területi könyvtári hálózatok képviselői). A szolgáltatás egyelőre lényegében egy új beszerzési és kölcsönzési modult jelent, de neve alapján ennél jóval több lesz a jövőben: Web-scale Management Service, vagyis webes nagyságrendű irányítási szolgáltatás. A lényege az, hogy miként pl. a Zoho project vagy a YouTube school, a szolgáltatás infrastruktúráját a könyvtár kiteszi a "felhőbe" - de leagalábbi a könyvtár falain kívülre. A harverrel és a szoftver karbantartásával, frissítésével neki már nem kell foglalkoznia. Amire koncentrálhat az a szoftver használata. A Tenessee Egyetem igen agresszív határidővel mindössze négy hét alatt állt át teljesen a régi rendszerükről az újra. Az előadók mind pénzügyi, mind szakmai szempontból eddig sikertörténetként írták le a szolgáltatás bevezetését.
Utolsó napon csak délelőtt voltak előadások, viszont kissé szerencsétlen időzítés miatt, az első kupac pont egybeesett azzal az idővel, ami alatt a szobákat el kellett hagyni, így mindössze néhány öt perce 'lighting talk' meghallgatására volt időm. Szerencsére a konferencia számomra legfontosabb (kulcs)előadását, Ross Singer "A kapcsolt könyvtári adatfelhő: ideje abbahagyni a gondolkodást és elkezdeni a linkelést" (The Linked Library Data Cloud: It's time to stop thinking and start linking" meg tudtam hallgatni. A "linked data" szerintem az a terület, ami a könyvtárak számára visszaadhatná a korábban az információszolgáltatás területén elfoglalt pozícióját - ugyanakkor mivel itthon kevéssé ismert, hogy miről van szó (még Tóth Máté egyébként kitünő PhD dolgozata a szemantikus web könyvtári vonatkozásairól is féllábú óriás a téma ignorálása miatt ;-) - bocs Máté, de én még idejében szóltam!), érdemes néhány mondatban kitérni rá. A linkelt adatok azt jelentik, hogy a könyvtári adatokat (elsősorban persze a katalógust, illetve az azonosító (vagy másképpen besorolási, authority) adatokat) a könyvtár a szemantikus web formátumainak megfelelően (RDF, RDFa, 3N stb.) is publikálja. Ez lehetőséget ad arra, hogy a katalógus adataihoz olyan adatokat csatoljunk, melyek a saját katalógusunkban nincsenek rögzítve, de más helyen (akár más könyvtárnál, akár teljesen más típusú adatszolgáltatónál) azonosítható módon jelen vannak. Ross a lemezek tracklistáinak példáit hozta fel. Még a legjobb könyvtári katalógusokban (pl. a Kongresszusi Könyvtárban) is ritka, hogy a számok szerzőit külön feltüntessék, ami megakadályozza, hogy azokat a számokat, melyeket sokan feldolgoztak (például klasszikus folk-, rock'n'roll- vagy Beatles-dalok) egy közös pontra mutassanak. Jelenleg nincsenek ilyen linkek, az olvasónak fogalma sincs a könyvtári katalógus alapján a dalok kontextusáról, arról hogy két Johnny B Good között mi az összefüggés. Egy másik példa: a VuFind a névazonosság alapján a szerzői ismertetőknél betölti a vonatkozó Wikipédia oldalt. Ám mi van akkor, ha a szerző neve nem egyedi? Mivel a VuFind csak karaktersorozat alapján dolgozik, nem tud két Michael Jacksont, az énekest és a harvardi filozófust megkülönböztetni. A szemantikus web technológia éppen ebben segít: minden entitásnak egyedi URL-je van, ami megosztható, így a katalógus adatai egyértelműsíthetők. A szemantikus technológia alapja az egyszerű logikai kijelentés: alany, állítmány, tárgy. Az esetek többségében nem csak az alany, hanem az állítmány is egyértelmű, vagyis nem csak az mondjuk, hogy A (könyv) címe B (karaktersorozat), hanem azt is, hogy a címet, mi (teszem azt) a Dublin Core-ban meghatározott értelemben tartjuk címnek, ami megint csak egyértelműsíti a különféle könyvtárak által tett állítások összevethetőségét. A minap a Katalistra küldte be valaki a német könyvtárak egyesített beazonosító állományának 3N formátumát, amiben kiegészítő attribútumként szerepelt a szerzők által írt művek zanzásított felsorolása, ami ahhoz pont elég, hogy két hasonló nevű szerző alapján eldöntsük, hogy valójában melyik URI azonosítja az egyiket és melyik a másikat. Gondoljuk el, hogy a könyvtárak rendelkezésére áll egy nagyon jól cizellált, meglehetősen nagy adathalmaz, amit egyéb szolgáltatók is kitűnően tudnának használni. A szemantikus technológiák, ezen belül a Linked Data ez egyik olyan eszköz, aminek a segítségével ez a potenciál újra kiaknázható.
Említettem, hogy a konferencia szervezési elvénél fogva alkalmas volt nagy beszélgetések lefolytatására. Számomra Ross Singerrel és Andrew Nagy-val különös öröm volt találkozni. Nagy (http://andrew.webitecture.org/) a VuFind alapítója. Néhány éve úgy volt, hogy a munkatársa leszek, amikor keresett maga mellé valakit a VuFind fejlesztésére, de végül a munkaadója nem akart külföldit szerződtetni. Andrew jelenleg a Serial Solutionsnél dolgozik és egyre inkább menedzser mint fejlesztő, ugyanakkor továbbra is ott van a könyvtári innováció első vonalában és bár hosszú évek óta kapcsolatban vagyunk, ez volt az első alkalom, hogy személyesen találkozhattunk. Ross (http://dilettantes.code4lib.org/blog/) a Jangle fejlesztője volt, de az utóbbi időben a Talis nevű vállalatnál (az angol OCLC) "az interoperabilitás és a nyílt szabványok bajnoka", valamint a code4lib egyik motorja. Nagy megtiszteltetés, hogy Ross ismerte a nevemet és az XC-nél folytatott tevékenységemet is. A konferencia előtt egy héttel részt vettem az OCLC által szervezett bostoni Mashathonon, ahol Roy Tennanttal és Karen Coombsszal (a "library web chick" néven ismert bloggerrel) ismerkedhettem meg, jól eset, hogy Roy Atlantában is odajött egy rövid beszélgetésre. Találkoztam a szemantikus technológiák, vagy egyéb webes témákat komolyan ismerő emberekkel, például Ken Varnummal (http://www.varnum.org/ken/), aki a michigani MLibrary egyik fejlesztője. Tőle végre megtudhattam, hogy mi a hasonlóság és különbség a Google Books és a HathiTrust között (Közbevetés: a GoogleBooks projekt a Michigani Egyetem könyvtárban indult, és mintaszerű, ahogy a projektet a weben keresztül ott nyomon lehet követni (pl. szkennelési tervek és naplók !!!) - ezzel szemben a hivatalos Google Books szájttól távol áll a bármiféle transzparencia, és akkor még finoman fogalmaztam).
A konferencia hashtegje a litaforum volt (http://twitter.com/#search?q=%23litaforum), és Adelle Frank Atlantai könyvtáros a blogjában még ki is gyűjtötte előadásonkénti bontásban a csiripeket: http://adellefrank.com/node/259 és az időközben elérhető előadások anyagit.
A Roy Tennant és Ross Singer kulcselőadásai a UStreamen érhetőek el http://www.ustream.tv/user/lita_ala/videos. A wikis előadás azonban sajnos nincs meg.
Az előadások írásos anyaga innen érhető el: http://connect.ala.org/node/113097.
1 komment
A bajai könyvtáros vándorgyűlésről
2010.07.17. 19:38 kirunews
Tegnap (2010-07-16) részt vettem (életemben először) a könyvtáros vándorgyűlésen. Csak egy napot voltam, délelőtt a FITT szekcióra ültem be, délután pedig a Magyar Elektronikus Könyvtár szekción voltam sikertelen vita-provokátor. A FITT szekció elég jó volt, viszonylag sok rövid, helyenként provokatív előadás előadás hangzott el. Kardos András, Németh Márton és Füzesi Károly főként azokat mondták el, amiket már többször elmondtak/leírtak különböző helyeken, de nyilván itt sokan voltak, akik korábban nem hallották őket. Habók Lilla és Mikulás Gábor egy olyan módszert mutattak be, amivel vezetők személyes megnyilvánulásait (pl. előadásokat, cikkeket?) lehet abból a szempontból vizsgálni és értékelni, hogy a szervezet hatékonyságát előmozdító, vagy éppen gátló tulajdonságokat vonultatnak-e fel. A módszer érdekes, és nyilván fontos lenne a cél is, de az öt személy 10-10 perces videóinak elemzése nekem nagyon kevés volt, nem vagyok benne biztos, de nagyon hajlok arra, hogy ez a mintanagyság egyszerűen nem elég nagy statisztikai méretű. Értem én, hogy az előadás célja a módszer ismertetése volt, de nagyon örültem volna, ha már egyáltalán belekezdtek a kipróbálásba, legalább komolyabban vették volna azzal, hogy egy teljes videót elemeznek, nem 10 percet. (Ezzel nem akarom elvenni Lilla és Gábor kedvét, nagyon jó lenne, ha folytatni tudnák azt, amibe belekezdtek, és le tudnának vonni tényleges konklúziókat, nem csak feldobni a labdát, hogy ezt is lehetne. Ilyen lehetnékből túl sok van - a saját házam táján is. De megcsinálni, az a valami.) Kun Dorottya arról beszélt, hogy a MOME könyvtárban hogyan alkalmazzák illetve tervezik alkalmazni a korszerű internetes eszközöket, részben a könyvtár.hu segítségével. A MEK szekcióba a könyvtáros egyesület betett két szponzori előadást, egy a FITT-nek is jutott - nem tudom, hogy a FITT-nek milyen beleszólása volt ebbe. Tóth Kornél a MTA Sztaki/Mongúz Kft. páros termékeit ismertette. Több előadás felvetette, hogy a könyvtárügy, vagy annak az a része, ami technológiailag releváns elég szervezetlen, és kellene valamilyen központ, ami ha nem is mondja meg az okosságot, segít a szakmai konszenzus kialakításában. Hát (ahogy Menzel mondja) nem tudom. 97-98 körül a Neumann-ház is ilyen céllal jött létre, de ezt a szerepet még Tószegi Zsuzsa idején sem tudta betölteni, Kitzinger Dávid pedig meg sem kísérelte. Lehetne sorolni a különféle nagyot álmodó központi projekteket, jó példát itthonról nem nagyon tudunk felmutatni. Szerintem először is nagyon sok nyilvános vitát kellene lefolytatni, ahelyett, ami most minden szinten folyik, ami a kamarilla-politika. Vagyis nagyon kevés nyilvánossággal működő döntéshozatali központok működnek. A FITT és a MEK szekció is szimptomatikusan mutatta (legalábbis nekem), hogy a résztvevők idegenkednek a nyílvános vitától, közös gondolkodástól. Lehet, hogy a folyosókon, kisebb körben sok mindenben egyetértenénk, de nem tudjuk közösen kinyilvánítani az álláspontunkat. Amíg jártam, történész konferenciákon is ez volt, szóval ez nem könyvtáros sajátosság. Viszont ahhoz, hogy szakmai konszenzus formálódjon alapkövetelmény hogy megismerjük egymás álláspontját. A FITT szekción elhangzott provokatívabb állásfoglalások (például András állásfoglalása az oktatással kapcsolatban) sem váltottak ki komolyabb visszhangot. Ahhoz szólt több mindenki hozzá, hogy a digitalizálás jogi szabályozása lényegében szinte lehetetlenné teszi a korszerű, releváns irodalom legális digitalizálását. Czupi Gyula, a nagykanizsai könyvtár vezetője számolt be róla, hogy talált olyan érvrendszert, amivel még egy kiadó is egyetértett, noha nyilvánvalóan az ő tevékenységük is a jogi szürke zónában jár.
A MEK szekció délelőtti előadásaival kapcsolatban Moldován István beszámolójára vagyok hagyatkozva. Az OSzK-ban (és egyébként egy EU-s projekt keretében) folyó igény szerinti (fizetős) digitalizálás teljesítménye: évi 40 könyv. Vagyis ennyi könyvet rendeltek meg bérdigitalizálás céljából, de még a sikeresebb helyeken sem több ez a szám 200-nál. Jó jelzőszám ez arra, hogy az igény szerinti digitalizálás jelen formájában nem igazán járható út.
István a maga szokott stílusában alaposan, egy órán keresztül beszélt a MEK elmúlt 10 évéről. Az én szereplésemnek az ötlete a MEK tisztújításon merült fel, ugyanis szerettem volna, ha a közgyűlésen vita folyna (igen, ez a személyes vesszőparipám) a MEK jövőjéről, ezért írtam egy főleg kérdéseket, alternatívákat soroló szöveget, amit kiküldtek a résztvevőknek. Idő hiányában azonban ez a programpont elmaradt, viszont a frissen megválasztott elnök, Horváth Sándor Domonkos felvetette, hogy menjünk el a vitával a Vándorgyűlésre. A vitapontokat azonban sajnos sem a MEK, sem a Vándorgyűlés honlapjára nem sikerült feltetettnem, holott az lett volna a tervem, hogy a résztvevőknek lesz esélyük előolvasni a szöveget (végül a szekció ideje alatt került fel ide). Vitát nekem sem sikerült provokálnom, Rónai Iván és HSD szóltak hozzá, de jóformán csak a szerzői jogi részhez (tudniillik ha a MEK-be nem kerül friss szöveg, akkor elsősorban a 70 évnél régebben meghallt szerzők műveit fogja őrizni, ami egyfajta múzeummá teszi a könyvtárat). Talán az lehet a megoldás, hogy a beiratkozott olvasók számára ugyanúgy legális lesz digitális anyagokat szolgáltatni, mint ahogy offline könyveket.
Mivel munkanap volt, a szekció után rohantam haza, úgyhogy nem sikerült beszélgetnem, - jóformán köszönnöm sem - az ott levő ismerőseimnek. Itt kérek tőlük elnézést.
Előadások (ha találok még, belinkelem):
- Füzesi Károly: Szolgáltatok, tehát...
- Habók Lilla-Mikulás Gábor: Szervezeti kultúra a könyvtári versenyképesség eszközeként
- Németh Márton: Hálózati könyvtári szolgáltatások Dániában
6 komment
Címkék: fitt mek
Kiáltvány digitális bölcsészetért
2010.07.13. 16:35 kirunews
Az alábbi szöveg a http://www.digitalhumanities.cnrs.fr/wikis/tcp/index.php?title=Anglais oldalon lévő angol nyelvű kiáltvány fordítása. (* = lásd a lap alján)
Összefüggésrendszer
Mi, a digitális bölcsészet művelői és szemlélői 2010. május 18.-án és 19.-én Párizsban a THATCamp konferencián gyűltünk össze.
A két nap során vitákat folytattunk, eszmét cseréltünk arról és közösen reflektáltunk arra, hogy mi is a digitális bölcsészet, továbbá megpróbáltuk elképzelni és kitalálni, hogy milyennek kellene lennie.
A - csupán az első lépést jelentő - tábor zárásakor egy, a digitális bölcsészetről szóló kiáltványt terjesztünk a kutatói közösségek és mindazok elé, akik részt vesznek a tudás létrehozásában, közzétételében, értékelésében és megőrzésében.
I. Meghatározás
1. A társadalom digitális fordulata megváltoztatja és kérdésessé teszi a tudás létrehozásának és elosztásának feltételeit.
2. Számunkra a digitális bölcsészet a társadalom- és bölcsészettudományok teljességét jelenti. A digitális bölcsészet nem tabula rasa. Ellenkezőleg: mindazon paradigmákra, képességekre és tudásra támaszkodik, melyek ezen tudományterületeket jellemezik, miközben mozgósítja a digitális technológia által elérhetővé vált eszközöket és egyedi szemléletmódot.
3. A digitális bölcsészet egy „transzdiszciplinát” jelöl, ami magába foglalja mindazokat a módszereket, rendszereket és heurisztikus szemléletmódokat melyek a bölcsészet- és társadalomtudományokban fellelhető digitális dolgokhoz köthetőek.
II. Helyzetfelmérés
4. Megfigyeljük
- hogy a társadalom- és bölcsészettudományok területén folytatott kisérletek száma az utolsó fél évszázadban megsokszorozódott. A legutóbbi időkben digitális bölcsészeti központok jöttek létre - melyek jelenleg csak a digitális bölcsészet területére jellemző prototípusok vagy alkalmazásterületek;
- hogy a számítógépes vagy a digitális szemléletmódoknak szigorúbb műszaki és így gazdasági, kutatási követelményei vannak; hogy ezek a követelmények lehetőséget biztosítanak az együttműködés erősítésére;
- hogy bár bizonyos számú, már bizonyított módszer létezik, ezek nem egyformán ismertek és hozzáférhetőek
- hogy sok közösség keletkezett a gyakorlat, az eszközök és különféle tudományközi célok terén osztott közös érdeklődésből - szöveges források kódolása, földrajzi információs rendszerek, lexikometria, a kultúrális, tudományos és műszaki örökség digitalizálása, webes térképészet, adatbányászat, 3D, szóbeli archívumok, digitális művészetek és hipermediális irodalom, stb. -, valamint hogy ezen közösségek a digitális bölcsészet tudományterületének kialakítása felé tartanak.
III. Bejelentés
5. Mi, a digitális bölcsészet művelői egy szolidáris, nyitott, befogadó és szabadon elérhető gyakorlati közösséget építünk.
6. Határok nélküli közösség vagyunk. Többnyelvű és több tudományágat átfogó közösség vagyunk.
7. Céljaink a tudás fejlődése, a kutatás minőségének javítása tudományterületünkön, a tudás és a közös örökség gazdagítása az oktatási-kutatási szférában és azon túl is.
8. Kívánjuk, hogy a digitális kultúra kerüljön be a kultúra huszonegyedik századi általános értelmezésébe.
IV. Útmutatók
9. Kívánjuk az adatokhoz és metaadatokhoz való nyílt hozzáférést; ezeket mind műszakilag, mind fogalmilag dokumentálni és együttműködő-képessé kell tenni.
10. Támogatjuk a módszerek, kódok, formátumok és kutatási eredmények terjesztését, cseréjét és szabad módosítását.
11. Kívánjuk a digitális bölcsészet oktatásának beépítését a társadalom- és bölcsészettudományi oktatásba. Szeretnénk látni digitális bölcsészeti diplomák létrehozását és az erre szentelt szakoktatás kifejlesztését. Végezetül szeretnénk, ha erre a szakismeretre tekintettel lennének az munkahelyi felvételi eljárásnál és a pályafutás során.
12. Elköteleztük magunkat arra, hogy felépítjük a közös szókincsen alapuló, minden érintett résztvevő munkája alapján formálódó közösségi szakismeretet. Szándékunk szerint ez a közösségi szakismeret közjó lesz. Tudományos lehetőség, de egyúttal a szakmai beilleszkedés lehetősége is valamennyi részterületbe.
13. Segíteni akarjuk a szakterületeken belül és szakterületek között felismert igényekkel kapcsolatos legjobb gyakorlatok meghatározását és elterjesztését, melyeket az érintett közösségeken belüli viták és megállapodások alapján kell kialakítani. A digitális bölcsészet alapvető nyitottsága ugyanakkor biztosítja a protokollok és víziók gyakorlati megközelítését, mely fenntartja a különféle, egymással versenyre kelő módszerek egymás mellett élésének a gondolkodás és a gyakorlat javát szolgáló jogát.
14. Kívánjuk a valós igényekre válaszoló, méretezhető digitális infrastruktúrák kialakítását. A digitális infrastruktúrák fokozatosan fognak felépülni a kutatói közösségekben sikeresnek bizonyuló módszerek és szemléletmódok alapján.
Frissítés (2012. I. 25.)
A forrásdokumentum időközben elkültözött ez eredetileg megadott címről, és a következő oldalon érhető el: http://tcp.hypotheses.org/411. Ugyanitt elérhető az eredeti angol szöveg német, francia, spanyol és számos egyéb nyelvű fordítása. (A linkekért köszönet Nagypál Lászlónak.)
1 komment
MySQL jegyzetek
2010.03.19. 15:00 kirunews
Hogyan keressük meg a sok rekordot tartalmazó táblákat?
show table status where Rows > 100000;
Adatbázis export gzippel
> mysqladmin -u<név> -p<jelszó> <adatbázis neve> | gzip > <adatbázis neve>.sql.gz
Szólj hozzá!
A nyertes pályázatáról
2010.01.21. 11:33 kirunews
Életemben nem írtam még pályázat-kritikát, de az előzmények ismeretében (Monok alulmaradása, az 'ismeretlen' Sajó Andreával szemben, majd Monok pályázatának publikálása, Sajóé nem publikálása, és a többi, amiről a Katalisten és a Konyvtáros.com-on lehetett értesülni) meglehetősen felcsigázta az érdeklődésemet, úgyhogy most (elsősorban magamnak, pedagógiai jelleggel) írok róla.
A legfontosabb: végre minden érdeklődő (az igazat megvallva néhány tucatnál nem lehet több, sajnos) megismerheti a pályázatot: http://www.oszk.hu/sajo_andrea/palyazat.pdf. A második, amit rögtön az elején szeretnék leszögezni: Sajó Andreát nem ismerem, látni is csak egyszer láttam, még Matáv-könyvtárosként egy Networkshop-konferencián, vagy 10 éve. Ha ennek a kritikának lesz némi éle, az nem az ő személye ellen szól (nem is szólhat, hiszen azt nem ismerem), hanem a pályázatban testet öltő teljesítményével kapcsolatos. Továbbá: a kritikában egyáltalán nem térek ki Monok pályázatára azon egyszerű okból, hogy nem nyert, tehát az ő pályázata nem releváns abból a szempontból, hogy milyen lesz az OSzK jövője, márpedig engem éppen ez érdekel, ezt próbálom kiolvasni Sajó Andrea pályázatából is.
Botrányosnak tartom, hogy egy OSzK főigazgatói poszt elnyerhető egy 18 és 1/3 oldalas (53 000 karaktert tartalmazó) pályázattal. Állítom, hogy ez a terjedelem nem alkalmas arra, hogy bármely jelölt meggyőzze a bírálókat, hogy nem csak a célokkal kapcsolatban vannak elépzelései, hanem a megvalósítás módjával, ütemezésével és erőforrásigényével is tisztában van. A pályázat nem sok konkrétumot tartalmaz a megvalósítással kapcsolatban; kirívó, hogy számadatok szinte egyáltalán nem, költségek pedig végképp nem szerepelnek. Úgy tűnik, hogy ezek a szempontok a fenntartó számra nem fontosak. Ha viszont ez igaz, akkor az újdonsült igazgatónő sem remélhet sok jót tőlük.
A pályázatból számomra nem jelenik meg egy átfogó könyvtár-vízió. Néha belemerül részletekbe, néhol csak felsorolást és 'stb.'-ket tartalmaz. A szöveg egy jelentékeny része olyannyira általános, sőt továbbmegyek: tankönyvpapír-ízű, hogy azt bármely tetszőleges könyvtárra, sőt néhol bármely intézményre alkalmazni lehetne. A szöveg nyelvezete nem arról árulkodik, hogy a szerző túl sok tapasztalatott szerzett volna az írásművészet gyakorlásában, gyakran enged a közhelyes fordulatok és a hivatalnokstílus csábításának (három példa, hogy világos legyen mire gondolok: "az 1952-től kiadásra került dokumentumok", "hiszen minden tevékenység egy-egy kis mozaik", végül "rendelkezik … üzleti szemléletű menedzser vénával"). Sajnos bennmaradt néhány helyesírási- vagy tollhiba is ("elektronikus fizetés mód bevezetése", "Z 39.50", "portáltecnológia"). Felejtsük el a pályázat nyelvi rétegét, mert a tartalom mellett ez nem érdekes - térjünk vissza a könyvtári vízióhoz.
Ami nagyon szimpatikus, hogy a pályázó felismerte, hogy az olvasó számára a dokumentumtípusok szerint tagolt rendszer értelmetlen. Ha teszem azt Sárazsadányról szeretnék informálódni, nem számít, hogy mi az adat forrása, illetve hadd dönthessem el én, hogy számít-e vagy sem. Ugynakkor nem világos, hogy mi is a megvalósítandó tevékenység, hiszen olyan programokat is sürget, amelyek nem tartoznak bele az OSzK igazgatójának döntési körébe. Például össze kellene vonni az ODR-t és a MOKKÁT, egyetérthetünk, de mind a kettő (ahogy tudom) konzorcium, vagyis az OSzK-nak csak egyetlen szavazata lehet a kérdésben. Össze kellene vonni a MATARKÁT és a HUMANUS-t - itt lényegében ugyanez a helyzet. Nem világos, hogy az OSzK vezetőjének mik lesznek ebben a kérdésben a lépései? Milyen érvekkel fogja meggyőzni a konzorciumi tagokat és a fenntartókat? Egekig dícséri a Könyvtárportált ("fantasztikus kezdeményezés"), de nem tisztázza azt a kérdést, hogy hogyan kellene a Könyvtárportálnak és az összevont ODR-MOKKÁNAK együttműködnie, vagy ezeket is össze kellene-e vonni.
Szintén szimpatikus a feladatorientált, lapos szervezet modellje. Nagyon drukkolok neki, hogy az OSzK-n belül tapasztalható széttagoltságot sikerüljön megszűntetnie és tényleg "egy irányba húzó" munkatársi gárdát sikerüljön kialakítani. Node: itt is hiányzik néhány konkrétum, leginkább annak a problémának a felvetése, amit például Reisz T. Csaba a MOL igazgatói pályázatában hangsúlyozott: az informatikai szakembergárda átlagosnál is nagyobb fluktuációja. Személyes tapasztalatból tudom, hogy ez a probléma még a nagy amerikai könyvtárakat is érinti, hiszen ott az informatikus számára az a dilemma: az egyetemi könyvtárban dolgozzak, vagy a IBM-nél? Márpedig Sajó Andrea egyik fő törekvése az OSzK szolgáltatásainak virtualizálása, aminek lépéseről a pályázat más helyein gyakorta értesülhetünk, sőt a pályázó ki is jelenti "A nemzeti könyvtár egyik új, lényeges feladatköre, hogy a digitális tartalom szolgáltatásában követhető, példamutató éllovas legyen.". Hogyan lehet éllovas egy olyan intézmény, melyben (tudomásom szerint) nem dolgozik hivatásos programozó (ezért települt a MOKKA-R és a Humanus Szegedre, Bozóhoz)? Továbbá: az osztályok a legjobb tudomásom szerint jelenleg is feladatkörök szerint vannak szervezve (pl. tájékoztatás, bibliográfiai feltárás stb., sőt tudomásom szerint egy olyan csoport is létezik - amit a pályázó hiányol és létrehozni kíván - mely teljes idejét webtartalmak előállítására fordítja) - valószinűleg csak az arányok kérdésesek. Vitatnám továbbá a következő mondatot: "Továbbra is működnek néhány főből álló szervezeti egységek (osztályok), melyek így nem hatékonyak." nem hiszem ugyanis, hogy egy szervezeti egység hatékonysága a nagyságán múlna - gondolom a szerző is inkább azt akarta mondani, hogy vannak (ilyen-olyan okok miatt) nem hatékony osztályok.
A pályázó néha belemerül részletekbe, például a szabadpolcos állomány adományokkal való feltöltése kapcsán sorjáznak az ötletek - bár némiképp szkeptikus vagyok abban, hogy pont az olvasók nagyját adó szegény bölcsészek fognak olyan értékes kézikönyveket adományozni, melyekre a könyvtárnak nincs pénze, de legyünk inkább optimisták. Máshol kardinális kérdések megoldási javaslatai, vagy egyáltalán felvetése került a 'stb.' kategóriájába.
Sajnálatos, de néhány ténybeli tévedés is található a pályázatban. Például állítása szerint a LibriVision-ben nincsenek analitikus rekordok. Ez csak abban az esetben igaz, ha az analitikus rekordokat a folyóirat-tartalomjegyzékek feltárásának eszközeként gondoljuk el, és megfeledkezünk a tanulmánykötetek tartalomjegyzékének feltárásáról (megjegyezném, hogy ez mint olvasónak komoly gond, hogy a tanulmánykötetek tartalomjegyzéke hol fel van dolgozva, hol nincs, a feldolgozottak pedig hol teljesek, hol nem - de erről a pályázatban nincs szó). Kérdéses tehát (számomra legalábbis az), hogy az idézett 1 millió monográfiából mennyi az ilyen analitikus rekord. Sajó számítása szerint az összes 8,6 millió dokumentum 3-5 éven belül feldolgozható, ha egy ember évi 200 napon napi 20 rekordot feldolgozna. Ha a már meglevő 1,6 millió dokumentumot levonjuk, és eltekintünk az analitikus feldolgozástól, akkor a 7 millió dokumentum feldolgozása 1750 munkaévet jelent, vagyis 5 év alatt csak akkor teljesíthető, ha 350 munkatárs dolgozik a feladaton (a jelenleg állomány kb. 500 fő) - ki-ki döntse el, hol a számítási hiba. A pályázó egy szót sem ejt a már feldolgozott, de nem Amicusban rögzített adatok (pl. a teljes Petrik, vagy a kézirattár katalógusa) átvételének lehetőségéről vagy a konverzió és az újbóli rögzítés költséghaszon-összevetéséről, se arról a kézenfekvő, és az OSzK-ban is alkalmazott módszerről, melynek során külső cégek végzik az adatbevitelt (az amerikai könyvtárak például Indiában vagy a Fülöp-szigeteken végeztetik az adatrögzítést).
A raktárak kérdése külön fejezetet kapott, de nem világos, hogy mennyire égető a kérdés: mikor szorul ki a könyvtár a meglévő helyről? Öt év? 25?
Szintén fontos kérdés az OPAC kérdése. Én - a pályázótól eltérően - különválasztanám az adatok előállításának és az adatok prezentációjának, keresésének kérdését (mellesleg ez utóbbit a szakirodalom és a library 2.0-ás gyakorlat is külön, "discovery interface" néven kezeli). Az Amicus leváltását nagyon óvatos hangon veti fel, érdemes idézni: "Az elmúlt évek tapasztalatai tehát arra engednek következtetni, hogy mindenképpen meg kell fontolni az AMICUS cseréjét". A problémáim: 1) nem biztos, hogy egyetlen „monolitikus” (ez nem Sajó Andrea kifejezése) integrált rendszert kellene beszerezni - lehet, hogy egy olyan csomag is megteszi, melyek alkotórészei szabványos felületeken (MARC, Z39.50, NCIP, SRW/SRU, OAI-PMH stb. stb.) együttműködnek egymással. 2) Naív elgondolás azt hinni, hogy az "az OSZK könyvtári rendszere kiemelt jelentőségű referenciahelyként is szolgálhatna" - ennek a mondatnak a folytatása ugyanis az szokott lenni: "épp ezért adjátok ingyen/olcsón". Ez lehet, hogy hatásos egy stat-up esetében, de nem hiszem, hogy jelentős árkedvezményt lehetne kicsikarni nemzetközi piacvezető szolgáltatóktól. 3) Nagyobb hangsúlyt adnék annak a szempontnak, hogy a szoftver megvételével ne álljon elő a beszállítóhoz-kötöttség (vendor lock-in) helyzete, amikor a könyvtár, vagy egy általa megbízott harmadik fél nem nyúlhat bele a szoftverbe. Már az is nagy eredmény lenne, ha a szoftvercsomag egy része ilyen lenne. 4) a szerencsésebb éghajlatú országokban a folyóiratok analitikus feltárását nem könyvtárak végzik, hanem a tartalomszolgáltatók (Elsevier, Thomson, JSTOR, és a többi), ennek megfelelően ezek az adatok nem is találhatók meg a saját adatbázisban, hanem API-kon keresztül csatlakoznak a könyvtári rendszerhez. Ennek megfelelően felteszem (de ha ez nem így van, akkor javítson ki, aki ezt olvassa) hogy legalábbis nem triviális a folyóirat-feltáró modul megléte. 5) A digitális tartalmat a pályázat "csatolható objektumként" képzeli el. Remélem ez nem azt jelenti, amire általában gondolni szoktak: vagyis nem egy strukturálatlan, csak teljes szövegűen kereshető, vagy csak képként elérhető fájl lebegett a szerző szeme előtt, hanem jól struktúrált szövegek kezelésére IS képes alrendszer.
Végezetül: Sajó Andrea pályázatában is visszaköszön az a hübrisz, ami úgy tűnik valami sajátos magyar lelki alkatra vezethető vissza, melynek legfőbb megnyilvánulása, hogy az adott vezető (mindegy, hogy a közintézmények mely ágazatát vesszük, a miniszterelnököktől a polgármestereken át a könyvtárigazgatókig) valamiféle (vérmérséklettől föggően: világ-, európai, közép-európai, kárpátmedencei és így tovább) centrumot látnak bele az intézménybe. Sajnos a szomorú valóság ezzel a csodálatos vízióval az, hogy néhány éven belül ezeket megvalósíthatatlanságuk miatt egy más víziók váltják fel. Vezető digitális tartalomszolgáltatóvá a könyvtár nem válhat úgy, hogy nincs meg a megfelelő szakembergárdája (most sajnos bizonyos területeken ez a helyzet, részben az általános világhelyzet okán), vagy ha dokumentumok másolásától való félelmében irreális technológiai célkitűzéseket támaszt (pl. képernyőképet se lehessen készíteni a tartalomról). A pályázat nem ejt szót egy fontos problémáról: a könyvtár saját maga megtermelte bevételének jelentős részét épp a digitális máslatok készítése adja. Csakhogy ez azzal jár, hogy ezeket csak az az ember látja, aki ezeket megfizeti - a többiek számára ezek láthatatlan dokumentumok. Vagyis hiába digitalizál a könyvtár dokumentumokat, ezek igazából nem csökkentik a kutató költségét, nem terjesztik a tudást széles rétegeknek (ami a könytár alapcélja lenne), sőt talán erőforrásokat von el a nyilvánosságnak szánt digitalizálás elől. Nem foglalkozik a pályázat a digitalizálás stratégiájával sem: mit digitalizáljon és hogyan (képként? nem struktúrált szövegként? cizellált XML-ként?)? Hogy viszonyuljon a könyvtár a "dolgok internete", az "összekapcsolt adatok" vagyis a szemantikus web kérdéséhez? Hogy viszonyuljon (a dorgáláson kívül) a könyves világ egyéb résztvevőihez?
Összegezve: ez a 18 és 1/3 oldal inkább csak újabb, az igazgatónő elképzeléseivel kapcsolatos kérdéseket vet fel, és nem kaptam választ arra az alapkérdésre, hogy az OSzK mit is fog csinálni a következő 5 évben. Előremutató lépés a digitális tartalmak kezelése és a szervezeti átalakítás, de a dolgozat alapján nem világos ezek konkrét formája. A pályázó mentségére legyen monda, a szöveg nem egy pontján kifejti, hogy ezt-vagy-azt a kérdést még alaposan meg kell vizsgálni. A döntéshozók felelősségét ezek a kitételek nem mentik.
Király Péter
utóirat
A bejegyzést többek tanácsára elküldtem Sajó Andreának, aki - mint kiderült - már olvasta (gondolom a konyvtaros.com-on), és meghívott, hogy személyesen vitatkozzunk, így a megjelenés után egy héttel én is megjelentem az OSzK igazgatói irodájában.
Néhány dolog, amit kifogásoltam, pl. a terjedelem, állásfoglalás a MOKKA/ODR, könyvtárportál, Humanus/Matarka ügyben a pályázati megkötés volt, szivesebben írt volna többet, részletesebben, egyébként az igazgatói pályázatok terjedelme általában ennyi szokott lenni (ez az én szememben megint csak a döntéshozók hanyagságát húzza alá).
A könyvtár jövőképével kapcsolatban nagyon sok mindenben egyetértettünk, például abban az elvben, hogy a kutatóknak lehetőség szerint ne kelljen feltétlenül elmenniük a könyvtárba, hogy hozzáférjenek a ritka vagy unikális dokumentumokhoz, hanem érhessék el az interneten keresztül. Ez csökkenti a nem budapesti bölcsészek (hiszen azért elsősorban bölcsészek használják a könyvtár gyűjteményét) jelenlegi esélyegyenlőtlenségét. Az egyik első dolog, amit szeretne bevezetni, az a raktári nyitvatartás meghosszabbítása (este hétig, és szombaton is). Az integrált rendszer/olvasói felület egyben vagy külön kérdése részletkérdés amellett, hogy az Amicus elavult, fontos, a könyvtár működéséhez szükséges modulok hiányoznak (pl. a kölcsönzés, ami a raktári nyilvántartást is rendbe tenné, és így a könyvek kiszolgálását is felgyorsítaná). Az informatikusok felvételére pedig a közintézetté válás teremt lehetőséget, ez a működési forma ugyanis lehetővé teszi, hogy a bérkerettel a jelenleginél szabadabban gazdálkodjanak, és differenciálhassanak a teljesítmények, betöltött szerepek fontossága szerint.
6 komment
Heller Ágnes: New York nosztalgia
2010.01.04. 09:25 kirunews
(könyvismertetés)
Heller Ágnes: New York nosztalgia. Pécs : Jelenkor, 2008. 288 oldal
Heller Ágnes már az első oldalon leszögezi, hogy ezt a könyvet a barátainak írta, azzal a céllal, hogy akik ismerik a "pesti" életét, azok ezúton megismerhesség a New Yorkban eltöltött időt is. Tisztességes kiindulópont, viszont a nem-barát olvasókkal sajnos nem számol a könyv, márpedig - gondolom - mi vagyunk többségben, akik nem ismerjük a szerző életének fordulatait olyan mértékben, hogy kapásból be tudjuk azonosítani Ferit (Fehér Ferenc, a második férj), Gyurit (? György, a fia), Misut (Vajda Mihály, filozófus, barát) és a többieket. Másrészt viszont ez a hiányosság arra sarkalja az olvasót, hogy alaposabban utánnanézzen ezeknek a fehér foltoknak.
Persze ez így, ebben a formában igazságtalan, hiszen a könyv egy-egy pontján néha fény derül némely dolgokra, pl. a könyv vége felé derül ki, hogy Fehér Ferenc 1994-ben halt meg - a gond az, hogy ez a szerző életének egyik fordulópontja volt, amire sokszor hivatkozik (Feri halála után...), és a könyv végéig nem tudjuk mihez kötni.
A könyv másik furcsaság a szerkesztetlensége. Az első kb. 2/3-ad rész jól megírt, egy-egy téma köré szervezett fejezetet tartalmaz. Az ezután következő részben viszont a szerző mesélő kedve alábbhagy, egyre többet idéz a naplójából, ami viszont legtöbbször inkább saját magának szóló emlékeztető mintsem memoárba illő passzus, pl. „Majd: «megint David Robertson vezényelt, most közepesen, de Christian Tetzlaff kitűnően játszotta Bartók II. hegedűversenyét. A Reich-szám nem volt oda-ne-rohanjak, a Beethoven VIII. szimfónia pedig színtelen.»”. A koncertekről és a kiállításokról szóló rész ennél fogva sokszor végtelennek tetsző felsorolásba fordul, mikor, mit látott, hallott. Azt hiszem, hogy egy jó szerkesztővel együttműködve ezeket a gyengeségeket el lehetett volna kerülni.
Mindezek ellenére (hogy végre a jó részre térjek), a könyv mégis izgalmas. Egyrészt bemutat egy olyan értelmiségi életideált, ami tele van izgalmas könyvekkel, koncertekkel, kiállításokkal, egyetemi szemináriumokkal és szimpóziumokkal. Én személyesen sosem éltem ezt az életet, de mindenesetre irígylésre méltó, hogy a szerző olyan életet él/élt, ahol tulajdonképpen csak a szenvedélyeire kellett időt töltenie - az ugyanis kiderül, hogy Heller Ágnes mind a tanítást, mind a művészeteket szenvedélyesen szereti. A gyermeke (gyermekei?) felnőttek, a férjével tökéletesen megegyezik a szenvedélye és nagyjából az érdeklődési köre is, anyagi gondjaik nem voltak (nagyon bölcsen arra a szintre hozták az igényeiket, amit meg tudtak engedni maguknak - bár úgy tűnik, hogy az amerikai egyetemi tanári állás sok mindenre lehetőséget ad, pl. 215 000 dollárért lakást venni - már ha jól értelmezem a következő párbeszédet: „Mennyi? - Kétszázhúsz. - Kétszáztizetötért megveszem. - Ilyen gyorsan dönt? - Igen.”).
A másik dolog, amin a könyv előtt sokat tűnődtem, hogy miért van az, hogy Heller Ágnes azon emberek közé tartozik, akik majdnem minden témához hozzászolnak. Nos, a könyv szerint személyes késztetést érez, hogy (majdnem) mindarról, amit elolvas, hall, vagy lát (persze egy bizonyos intellektuális szinten túl), írjon valamit: cikket, tanulmányt, könyvet. Egy másik Heller Ágnes könyvben, a Filozófiám történetében (amit tulajdonképpen a New York nosztalgia keltette kíváncsiság hatására vettem meg) közölt bibliográfia 50 Heller-könyvet sorol fel - ezen felül vannak még a cikkek, tanulmányok, konferencia-előadások stb. bár nyilvánvaló, hogy ezek, és a könyvek között van átfedés.
A harmadik dolog, amiért érdemes a könyvet elolvasni, az maga New York. Úgy tűnik, hogy New York mint téma kimeríthetetlen, Dos Passos, Woody Allen, vagy a Jóbarátok után is lehet egy csomó érdekes dolgot mondani róla, pl. lakásberendezésről, a Magyarországon mostanában újra megjelenő condominium típusú társasházról és annak belső életéről (nem tudom, hogy itthon van-e efféle lakóközösségi élet), az alkotmányba foglalt használtkönyv-piacról, egyes utcák vagy városrészek jellegzetességeiről illetve a jellegzetességek dinamikus változásairól (ami akár 20 év alatt is drasztikus változásokkal járhat).
Végül nagyon érdekes az egyetemi élet bemutatása. Régi vesszőparipám, hogy az amerikai egyetemeken azért működhet az a rendszer, hogy a bevételek egy jelentős részét az egykor volt hallgatók adományai adják, mert azok jó szívvel gondolnak vissza egyetemi éveikre, méghozzá azért, mert az egyetem nagyon sokat tett azért, hogy ők tényleg a tanulmányaikra tudjanak összpontosítani - ez megjelenik a tanulmányi rend kialakításában, a könyvtárak felszereltségében, végül de nem utolsósorban: az adminisztratív személyzet kiválasztásában is. Heller Ágnes (nem áll a számra, hogy azt írjam csak, hogy "Heller") külön bekezdéseket szentel a tanszéki titkárnőjének, akinek legfontosabb munkahelyi feladata, hogy a tanszék "anyja" legyen. Jut eszembe: úgy tűnik, hogy a szerző nem jár könyvtárba, ha valami kell, akkor vagy megveszi, vagy egy tanítványát kéri meg, hogy kölcsönözze ki. További furcsaság, hogy bár azt írja szereti a jazzt, egyetlen jazz elményt (koncertet, lemezt, vagy akár csak jazz zenészt) sem említ - szemben a bőven tárgyalt komolyzenével. Azt hiszem, hogy azt csak a könyvei, cikkei alapján lehet megítélni, hogy milyen szerepet kaptak a filozófusokkal való személyes kapcsolatai a filozófiájában. A könyv alapján úgy érzem, hogy a személyes kapcsolatnak nagy hatása volt a gondolkodására - nem biztos, hogy ugyanígy hatottak volna pusztán a művek. Legalábbis a könyv alapján ez a benyomásom.
Aki Heller Ágnes filozófiai gondolatait keresi a könyvben, az nem nagyon fog ilyeneket találni - hacsak nem a nálam sokkal válytfülűbb olvasók, akik egy-egy utalást vissza tudnak vezetni más olvasás vagy előadás élményeikre. Nekem ilyenek eddig nem nagyon voltak. Viszont a köny hatására nekikezdtem két másik könyvnek: Fehér Ferenc-Heller Ágnes: Egy forradalom üzenete (Magyarország 1956) (Budapest : Kossuth Kiadó (!!!), 1989 (!!!)), és Heller Ágnes: Filozófiám története (Budapest : Múlt és Jövő Kiadó, 2009), hátha ebből többet megtudok a szerző gondolkodásának eredményeiről, továbbá tervezek beszerezni valamiféle konkrétabb életrajzi művet is, hogy a kronológia és számos nyitott életrajzi-történeti kérdésre választ kapjak (az már 90 oldal után kiderült, hogy a Filozófiám története sem ad választ az életrajzi kérdésekre, de még a Budapesti Iskolával kapcsolatban is sok a bizonytalanság).
Szólj hozzá!
biológiai textológia
2009.05.11. 13:32 kirunews
Peter Robinson Co-director of Institute for Textual Scholarship and Electronic Editing (University of Birmingham, Department of Theology & Religion)
Adrian C. Barbrook, Christopher J. Howe - Norman Blake - P. Robinson: A Canterbury Mesék törzsfejlődése (The phylogeny of The Canterbury Tales, Nature, Vol 394., 27 AUGUST 1998, p. 839.)
A teljes műből 80 kézirat maradt fenn. Ebből a Bathi asszonyság bevezetőjét tartalmazó 58-at elemeztek az evolúciós biológia eszközei segítségével. Több kézirat közös őssel rendelkezik, ami által csoportosítani lehet. A hagyományos kézi elemzés korlátos: igazán csak néhány forrást vehet figyelembe, a Canterbury mesék esetében túl sok forrás van.
A történeti rekosntrukció elve azonban hasonló ahhoz, a számítógépesített technikához, amit az evolúciós biológusok dolgoztak ki különféle organizmusok törzsfejlődési fáinak megállapításához adatsorok alapján. A projekt ezeket a törzsfejlődési technikát alkalmazta a Canterbury mesék adott részének összes fennmaradt kéziratára. A kutatók szerint ez az első ilyen elemzés.
a szétválasztás-dekompozíció (split decomposition) módszerét alkamaztát, amit a SplitTree program implementál, - a PAUP osztályozó* elemzése (cladistic analysys) mellett. A mellékelt ábra 44 kézirat SplitTree-el meghatározott ágrajzát mutatja (a PAUP lényegében ugyanezt mutatta). Néhány csoport (A, B, C/D, E, F) ugyannanak a közös ősnek a leszármazottja, a maradék 14 kéziratnak feltehetően több őse van (több kéziratból másolták - vagy szándékosan, vagy másolás közben kicserélték a másolt forrást). Ezeket a kéziratokat a szövegek különböző részei alapján generált ágrajzok összevetésével sikerült beazonosítani, ami megmutatta, hogy az elemésbeli helyzetük drámaian megváltotott a kiválasztott szövegrésztől függően. A középső pont valószínűleg a teljes hagyomány ősét jelenti. Az O-val jelölt kéziratcsoport különösen fontos: a központ-közeli helyzetük azt sugalja, hogy valamennyien az eredeti Chauser-kézirat leszármazottjai, és ezért fontos bizonyítékok lehetnek az eredeti kézirattal kapcsolatban. A kutatók azonban legtöbbjüket ignorálták.
Az elemzés alapján (és más bizonyítékok is ezt valószinűsítik) azt a következtetést vontuk le, hogy az egész tradíció ősforrása, Chauser saját példánya nem egy végleges vagy letisztázott példány volt, hanem egy olyan munkapéldány, ami tartalmazta (példának okéért) Chauser saját jegyzeteit törlendő vagy éppen beszúrandó passzusokról, illetve egyes részek alternatív vázlatait. Ez a feltevés majd idővel arra ösztönözheti a szerkesztőket, hogy elkészítsék a Canterbury mesék radikálisan eltérő szövegváltozatát. Az eredmények megmutatják az almalmazott törzsfejlődési technikáknak (különösen a szétválasztás-dekompozíciónak) a sok példányban fennmaradt terjedelmes szövegek elemzésében hasznosítható erejét.
Hivatkozások:
- Blake, N. F. The Textual Tradition of The Canterbury Tales (Edward Arnold, London, 1985).
- Huson, D. H. Bioinformatics 14, 68–73 (1998).
- Swofford, D. L. PAUP Version 3.1.1. (Smithsonian Institute, Washington DC, 1993).
- Robinson, P. M. W. in The Canterbury Tales Project: Occasional Papers Vol. II (eds Blake, N.F. & Robinson, P.M.W.) 69–132 (Office for Humanities Communication, London, 1997).
*cladistic: a biológiai taxonómia rendszere, ami a taxonokat kizárólag a szülőcsoportokban nem található közös jellemzők alapján határozza meg és a kikövetkeztetett evolúciós kapcsolatok alapján rendezi a taxonokat összekapcsolódó hierarchiába úgy, hogy adott taxon minden elemének ugyanazok az ősei. (http://www.merriam-webster.com/dictionary/cladistic)
Szólj hozzá!
picasa
2009.05.09. 18:24 kirunews
- Teleki László Városi Könyvtár és Művelődési Központ (Pásztó)
- Peter Szaffko
- Justh Városi Könyvtár (Orosháza)
- Pataki Márta
- Konyvtar (Szegedi Egyetemi Könyvtár?)
- MKE Gyermekkönyvtáros Szekció
- MKE Fejér Megyei Egyesülete
- konyvtarszhek (Szombathelyi Egyetemi Könyvtár?)
- Kálváriások (iskolai könyvtár Gyöngyösön?) http://code.google.com/intl/hu/apis/picasaweb/overview.html